2. makemore (part 1): implementing a bigram character-level language model#
import sys
IN_COLAB = "google.colab" in sys.modules
if IN_COLAB:
print("Cloning repo...")
!git clone --quiet https://github.com/ckaraneen/micrograduate.git > /dev/null
%cd micrograduate
print("Installing requirements...")
!pip install --quiet uv
!uv pip install --system --quiet -r requirements.txt
Intro#
Just like micrograd before it, here, step-by-step with everything spelled-out, we will build makemore: a bigram character-level language model. We’re going to build it out slowly and together! But what is makemore? As the name suggests, makemore makes more of things that you give it. names.txt is an example dataset. Specifically, it is a very large list of different names. If you train makemore on this dataset, it will learn to make more of name-like things, basically more unique names! So, maybe if you have a baby and you’re looking for a new, cool-sounding unique name, makemore might help you. Here are some examples of such names that the makemore will be able to generate:
dontell
khylum
camatena
aeriline
najlah
sherrith
ryel
irmi
taislee
mortaz
akarli
maxfelynn
biolett
zendy
laisa
halliliana
goralynn
brodynn
romima
chiyomin
loghlyn
melichae
mahmed
irot
helicha
besdy
ebokun
lucianno
dontell, irot, zendy, and so on, you name it! So under the hood, makemore is a character-level language model. That means that it’s treating every single line (i.e. name) of its training dataset as an example. And each example is treated as a sequence of individual characters. For instance, it treats the name reese as the sequence of characters: r, e, e, s, e. That is the level on which we are building out makemore. Basically, its purpose is this: given a character, it can predict the next character in the sequence based upon the names that it has seen so far. Now, we’re actually going to implement a large number of character-level language models, following a few key innovations:
Bigram (one character predicts the next one with a lookup table of counts)
MLP, following Bengio et al. 2003
CNN, following DeepMind WaveNet 2016 (in progress…)
RNN, following Mikolov et al. 2010
LSTM, following Graves et al. 2014
GRU, following Kyunghyun Cho et al. 2014
Transformer, following Vaswani et al. 2017
In fact, the transformer we are going to build will be the equivalent of GPT-2. Kind of a big deal, since it’s a modern network and by the end of this guide you’ll actually understand how it works at the level of characters. Later on, we will probably spend some time on the word level, so we can generate documents of words, not just segments of characters. And then we’re probably going to go into image and image-text networks such as DALL-E, Stable Diffusion, and so on. But first, let’s jump into character-level modeling.
Building a bigram language model#
Let’s start by reading all the names into a list:
words = open("names.txt").read().splitlines()
words[:10]
['emma',
'olivia',
'ava',
'isabella',
'sophia',
'charlotte',
'mia',
'amelia',
'harper',
'evelyn']
Now, we want to learn a bit more about this dataset.
len(words)
32033
len(min(words, key=len)) # shortest
2
len(max(words, key=len)) # longest
15
Let’s think through our very first language model. A character-level language model is predicting the next character in the sequence given already some concrete sequence of characters before it. What we have to realize here is that every single word like isabella is actually quite a few examples packed in that single word. Because, let’s think: what is a word telling us really? It’s saying that the character i is a very likely character to come first in the sequence that constitutes a name. The character s is likely to come after i, the character a is likely to come after is, the character b is likely to come after isa, and so on all the way to a following isabell. And then there’s one more important piece of information in here. And that is that after isabella, the word is very likely to end. So, time to build our first network: a bigram language model. In these, we are working with two characters at a time. So, we are only looking for one character we are given and we are trying to predict the next character in a sequence. For example, in the name charlotte, we ask: what characters are likely to follow r? In the name sophia: we ask what characters are likely to follow p? And so on. This mean we are just modeling that local structure. Meaning, we only look at the previous character, even though there might be a lot of useful information before it. This is a very simple model, which is why it’s a great place to start! We can learn about the statistics of which characters are likely to follow which other characters by counting. So by iterating over all names, we can count how often each consecutive pair (bigram) of characters appears.
b = {}
for w in words:
chs = ["."] + list(w) + ["."]
for ch1, ch2 in zip(chs, chs[1:]):
bigram = (ch1, ch2)
b[bigram] = b.get(bigram, 0) + 1
Notice that we have also added the character . to signify the start and end of each word. And obviously, the variable b now holds the statistics of the entire dataset.
sorted(b.items(), key=lambda tup: tup[1], reverse=True)
[(('n', '.'), 6763),
(('a', '.'), 6640),
(('a', 'n'), 5438),
(('.', 'a'), 4410),
(('e', '.'), 3983),
(('a', 'r'), 3264),
(('e', 'l'), 3248),
(('r', 'i'), 3033),
(('n', 'a'), 2977),
(('.', 'k'), 2963),
(('l', 'e'), 2921),
(('e', 'n'), 2675),
(('l', 'a'), 2623),
(('m', 'a'), 2590),
(('.', 'm'), 2538),
(('a', 'l'), 2528),
(('i', '.'), 2489),
(('l', 'i'), 2480),
(('i', 'a'), 2445),
(('.', 'j'), 2422),
(('o', 'n'), 2411),
(('h', '.'), 2409),
(('r', 'a'), 2356),
(('a', 'h'), 2332),
(('h', 'a'), 2244),
(('y', 'a'), 2143),
(('i', 'n'), 2126),
(('.', 's'), 2055),
(('a', 'y'), 2050),
(('y', '.'), 2007),
(('e', 'r'), 1958),
(('n', 'n'), 1906),
(('y', 'n'), 1826),
(('k', 'a'), 1731),
(('n', 'i'), 1725),
(('r', 'e'), 1697),
(('.', 'd'), 1690),
(('i', 'e'), 1653),
(('a', 'i'), 1650),
(('.', 'r'), 1639),
(('a', 'm'), 1634),
(('l', 'y'), 1588),
(('.', 'l'), 1572),
(('.', 'c'), 1542),
(('.', 'e'), 1531),
(('j', 'a'), 1473),
(('r', '.'), 1377),
(('n', 'e'), 1359),
(('l', 'l'), 1345),
(('i', 'l'), 1345),
(('i', 's'), 1316),
(('l', '.'), 1314),
(('.', 't'), 1308),
(('.', 'b'), 1306),
(('d', 'a'), 1303),
(('s', 'h'), 1285),
(('d', 'e'), 1283),
(('e', 'e'), 1271),
(('m', 'i'), 1256),
(('s', 'a'), 1201),
(('s', '.'), 1169),
(('.', 'n'), 1146),
(('a', 's'), 1118),
(('y', 'l'), 1104),
(('e', 'y'), 1070),
(('o', 'r'), 1059),
(('a', 'd'), 1042),
(('t', 'a'), 1027),
(('.', 'z'), 929),
(('v', 'i'), 911),
(('k', 'e'), 895),
(('s', 'e'), 884),
(('.', 'h'), 874),
(('r', 'o'), 869),
(('e', 's'), 861),
(('z', 'a'), 860),
(('o', '.'), 855),
(('i', 'r'), 849),
(('b', 'r'), 842),
(('a', 'v'), 834),
(('m', 'e'), 818),
(('e', 'i'), 818),
(('c', 'a'), 815),
(('i', 'y'), 779),
(('r', 'y'), 773),
(('e', 'm'), 769),
(('s', 't'), 765),
(('h', 'i'), 729),
(('t', 'e'), 716),
(('n', 'd'), 704),
(('l', 'o'), 692),
(('a', 'e'), 692),
(('a', 't'), 687),
(('s', 'i'), 684),
(('e', 'a'), 679),
(('d', 'i'), 674),
(('h', 'e'), 674),
(('.', 'g'), 669),
(('t', 'o'), 667),
(('c', 'h'), 664),
(('b', 'e'), 655),
(('t', 'h'), 647),
(('v', 'a'), 642),
(('o', 'l'), 619),
(('.', 'i'), 591),
(('i', 'o'), 588),
(('e', 't'), 580),
(('v', 'e'), 568),
(('a', 'k'), 568),
(('a', 'a'), 556),
(('c', 'e'), 551),
(('a', 'b'), 541),
(('i', 't'), 541),
(('.', 'y'), 535),
(('t', 'i'), 532),
(('s', 'o'), 531),
(('m', '.'), 516),
(('d', '.'), 516),
(('.', 'p'), 515),
(('i', 'c'), 509),
(('k', 'i'), 509),
(('o', 's'), 504),
(('n', 'o'), 496),
(('t', '.'), 483),
(('j', 'o'), 479),
(('u', 's'), 474),
(('a', 'c'), 470),
(('n', 'y'), 465),
(('e', 'v'), 463),
(('s', 's'), 461),
(('m', 'o'), 452),
(('i', 'k'), 445),
(('n', 't'), 443),
(('i', 'd'), 440),
(('j', 'e'), 440),
(('a', 'z'), 435),
(('i', 'g'), 428),
(('i', 'm'), 427),
(('r', 'r'), 425),
(('d', 'r'), 424),
(('.', 'f'), 417),
(('u', 'r'), 414),
(('r', 'l'), 413),
(('y', 's'), 401),
(('.', 'o'), 394),
(('e', 'd'), 384),
(('a', 'u'), 381),
(('c', 'o'), 380),
(('k', 'y'), 379),
(('d', 'o'), 378),
(('.', 'v'), 376),
(('t', 't'), 374),
(('z', 'e'), 373),
(('z', 'i'), 364),
(('k', '.'), 363),
(('g', 'h'), 360),
(('t', 'r'), 352),
(('k', 'o'), 344),
(('t', 'y'), 341),
(('g', 'e'), 334),
(('g', 'a'), 330),
(('l', 'u'), 324),
(('b', 'a'), 321),
(('d', 'y'), 317),
(('c', 'k'), 316),
(('.', 'w'), 307),
(('k', 'h'), 307),
(('u', 'l'), 301),
(('y', 'e'), 301),
(('y', 'r'), 291),
(('m', 'y'), 287),
(('h', 'o'), 287),
(('w', 'a'), 280),
(('s', 'l'), 279),
(('n', 's'), 278),
(('i', 'z'), 277),
(('u', 'n'), 275),
(('o', 'u'), 275),
(('n', 'g'), 273),
(('y', 'd'), 272),
(('c', 'i'), 271),
(('y', 'o'), 271),
(('i', 'v'), 269),
(('e', 'o'), 269),
(('o', 'm'), 261),
(('r', 'u'), 252),
(('f', 'a'), 242),
(('b', 'i'), 217),
(('s', 'y'), 215),
(('n', 'c'), 213),
(('h', 'y'), 213),
(('p', 'a'), 209),
(('r', 't'), 208),
(('q', 'u'), 206),
(('p', 'h'), 204),
(('h', 'r'), 204),
(('j', 'u'), 202),
(('g', 'r'), 201),
(('p', 'e'), 197),
(('n', 'l'), 195),
(('y', 'i'), 192),
(('g', 'i'), 190),
(('o', 'd'), 190),
(('r', 's'), 190),
(('r', 'd'), 187),
(('h', 'l'), 185),
(('s', 'u'), 185),
(('a', 'x'), 182),
(('e', 'z'), 181),
(('e', 'k'), 178),
(('o', 'v'), 176),
(('a', 'j'), 175),
(('o', 'h'), 171),
(('u', 'e'), 169),
(('m', 'm'), 168),
(('a', 'g'), 168),
(('h', 'u'), 166),
(('x', '.'), 164),
(('u', 'a'), 163),
(('r', 'm'), 162),
(('a', 'w'), 161),
(('f', 'i'), 160),
(('z', '.'), 160),
(('u', '.'), 155),
(('u', 'm'), 154),
(('e', 'c'), 153),
(('v', 'o'), 153),
(('e', 'h'), 152),
(('p', 'r'), 151),
(('d', 'd'), 149),
(('o', 'a'), 149),
(('w', 'e'), 149),
(('w', 'i'), 148),
(('y', 'm'), 148),
(('z', 'y'), 147),
(('n', 'z'), 145),
(('y', 'u'), 141),
(('r', 'n'), 140),
(('o', 'b'), 140),
(('k', 'l'), 139),
(('m', 'u'), 139),
(('l', 'd'), 138),
(('h', 'n'), 138),
(('u', 'd'), 136),
(('.', 'x'), 134),
(('t', 'l'), 134),
(('a', 'f'), 134),
(('o', 'e'), 132),
(('e', 'x'), 132),
(('e', 'g'), 125),
(('f', 'e'), 123),
(('z', 'l'), 123),
(('u', 'i'), 121),
(('v', 'y'), 121),
(('e', 'b'), 121),
(('r', 'h'), 121),
(('j', 'i'), 119),
(('o', 't'), 118),
(('d', 'h'), 118),
(('h', 'm'), 117),
(('c', 'l'), 116),
(('o', 'o'), 115),
(('y', 'c'), 115),
(('o', 'w'), 114),
(('o', 'c'), 114),
(('f', 'r'), 114),
(('b', '.'), 114),
(('m', 'b'), 112),
(('z', 'o'), 110),
(('i', 'b'), 110),
(('i', 'u'), 109),
(('k', 'r'), 109),
(('g', '.'), 108),
(('y', 'v'), 106),
(('t', 'z'), 105),
(('b', 'o'), 105),
(('c', 'y'), 104),
(('y', 't'), 104),
(('u', 'b'), 103),
(('u', 'c'), 103),
(('x', 'a'), 103),
(('b', 'l'), 103),
(('o', 'y'), 103),
(('x', 'i'), 102),
(('i', 'f'), 101),
(('r', 'c'), 99),
(('c', '.'), 97),
(('m', 'r'), 97),
(('n', 'u'), 96),
(('o', 'p'), 95),
(('i', 'h'), 95),
(('k', 's'), 95),
(('l', 's'), 94),
(('u', 'k'), 93),
(('.', 'q'), 92),
(('d', 'u'), 92),
(('s', 'm'), 90),
(('r', 'k'), 90),
(('i', 'x'), 89),
(('v', '.'), 88),
(('y', 'k'), 86),
(('u', 'w'), 86),
(('g', 'u'), 85),
(('b', 'y'), 83),
(('e', 'p'), 83),
(('g', 'o'), 83),
(('s', 'k'), 82),
(('u', 't'), 82),
(('a', 'p'), 82),
(('e', 'f'), 82),
(('i', 'i'), 82),
(('r', 'v'), 80),
(('f', '.'), 80),
(('t', 'u'), 78),
(('y', 'z'), 78),
(('.', 'u'), 78),
(('l', 't'), 77),
(('r', 'g'), 76),
(('c', 'r'), 76),
(('i', 'j'), 76),
(('w', 'y'), 73),
(('z', 'u'), 73),
(('l', 'v'), 72),
(('h', 't'), 71),
(('j', '.'), 71),
(('x', 't'), 70),
(('o', 'i'), 69),
(('e', 'u'), 69),
(('o', 'k'), 68),
(('b', 'd'), 65),
(('a', 'o'), 63),
(('p', 'i'), 61),
(('s', 'c'), 60),
(('d', 'l'), 60),
(('l', 'm'), 60),
(('a', 'q'), 60),
(('f', 'o'), 60),
(('p', 'o'), 59),
(('n', 'k'), 58),
(('w', 'n'), 58),
(('u', 'h'), 58),
(('e', 'j'), 55),
(('n', 'v'), 55),
(('s', 'r'), 55),
(('o', 'z'), 54),
(('i', 'p'), 53),
(('l', 'b'), 52),
(('i', 'q'), 52),
(('w', '.'), 51),
(('m', 'c'), 51),
(('s', 'p'), 51),
(('e', 'w'), 50),
(('k', 'u'), 50),
(('v', 'r'), 48),
(('u', 'g'), 47),
(('o', 'x'), 45),
(('u', 'z'), 45),
(('z', 'z'), 45),
(('j', 'h'), 45),
(('b', 'u'), 45),
(('o', 'g'), 44),
(('n', 'r'), 44),
(('f', 'f'), 44),
(('n', 'j'), 44),
(('z', 'h'), 43),
(('c', 'c'), 42),
(('r', 'b'), 41),
(('x', 'o'), 41),
(('b', 'h'), 41),
(('p', 'p'), 39),
(('x', 'l'), 39),
(('h', 'v'), 39),
(('b', 'b'), 38),
(('m', 'p'), 38),
(('x', 'x'), 38),
(('u', 'v'), 37),
(('x', 'e'), 36),
(('w', 'o'), 36),
(('c', 't'), 35),
(('z', 'm'), 35),
(('t', 's'), 35),
(('m', 's'), 35),
(('c', 'u'), 35),
(('o', 'f'), 34),
(('u', 'x'), 34),
(('k', 'w'), 34),
(('p', '.'), 33),
(('g', 'l'), 32),
(('z', 'r'), 32),
(('d', 'n'), 31),
(('g', 't'), 31),
(('g', 'y'), 31),
(('h', 's'), 31),
(('x', 's'), 31),
(('g', 's'), 30),
(('x', 'y'), 30),
(('y', 'g'), 30),
(('d', 'm'), 30),
(('d', 's'), 29),
(('h', 'k'), 29),
(('y', 'x'), 28),
(('q', '.'), 28),
(('g', 'n'), 27),
(('y', 'b'), 27),
(('g', 'w'), 26),
(('n', 'h'), 26),
(('k', 'n'), 26),
(('g', 'g'), 25),
(('d', 'g'), 25),
(('l', 'c'), 25),
(('r', 'j'), 25),
(('w', 'u'), 25),
(('l', 'k'), 24),
(('m', 'd'), 24),
(('s', 'w'), 24),
(('s', 'n'), 24),
(('h', 'd'), 24),
(('w', 'h'), 23),
(('y', 'j'), 23),
(('y', 'y'), 23),
(('r', 'z'), 23),
(('d', 'w'), 23),
(('w', 'r'), 22),
(('t', 'n'), 22),
(('l', 'f'), 22),
(('y', 'h'), 22),
(('r', 'w'), 21),
(('s', 'b'), 21),
(('m', 'n'), 20),
(('f', 'l'), 20),
(('w', 's'), 20),
(('k', 'k'), 20),
(('h', 'z'), 20),
(('g', 'd'), 19),
(('l', 'h'), 19),
(('n', 'm'), 19),
(('x', 'z'), 19),
(('u', 'f'), 19),
(('f', 't'), 18),
(('l', 'r'), 18),
(('p', 't'), 17),
(('t', 'c'), 17),
(('k', 't'), 17),
(('d', 'v'), 17),
(('u', 'p'), 16),
(('p', 'l'), 16),
(('l', 'w'), 16),
(('p', 's'), 16),
(('o', 'j'), 16),
(('r', 'q'), 16),
(('y', 'p'), 15),
(('l', 'p'), 15),
(('t', 'v'), 15),
(('r', 'p'), 14),
(('l', 'n'), 14),
(('e', 'q'), 14),
(('f', 'y'), 14),
(('s', 'v'), 14),
(('u', 'j'), 14),
(('v', 'l'), 14),
(('q', 'a'), 13),
(('u', 'y'), 13),
(('q', 'i'), 13),
(('w', 'l'), 13),
(('p', 'y'), 12),
(('y', 'f'), 12),
(('c', 'q'), 11),
(('j', 'r'), 11),
(('n', 'w'), 11),
(('n', 'f'), 11),
(('t', 'w'), 11),
(('m', 'z'), 11),
(('u', 'o'), 10),
(('f', 'u'), 10),
(('l', 'z'), 10),
(('h', 'w'), 10),
(('u', 'q'), 10),
(('j', 'y'), 10),
(('s', 'z'), 10),
(('s', 'd'), 9),
(('j', 'l'), 9),
(('d', 'j'), 9),
(('k', 'm'), 9),
(('r', 'f'), 9),
(('h', 'j'), 9),
(('v', 'n'), 8),
(('n', 'b'), 8),
(('i', 'w'), 8),
(('h', 'b'), 8),
(('b', 's'), 8),
(('w', 't'), 8),
(('w', 'd'), 8),
(('v', 'v'), 7),
(('v', 'u'), 7),
(('j', 's'), 7),
(('m', 'j'), 7),
(('f', 's'), 6),
(('l', 'g'), 6),
(('l', 'j'), 6),
(('j', 'w'), 6),
(('n', 'x'), 6),
(('y', 'q'), 6),
(('w', 'k'), 6),
(('g', 'm'), 6),
(('x', 'u'), 5),
(('m', 'h'), 5),
(('m', 'l'), 5),
(('j', 'm'), 5),
(('c', 's'), 5),
(('j', 'v'), 5),
(('n', 'p'), 5),
(('d', 'f'), 5),
(('x', 'd'), 5),
(('z', 'b'), 4),
(('f', 'n'), 4),
(('x', 'c'), 4),
(('m', 't'), 4),
(('t', 'm'), 4),
(('z', 'n'), 4),
(('z', 't'), 4),
(('p', 'u'), 4),
(('c', 'z'), 4),
(('b', 'n'), 4),
(('z', 's'), 4),
(('f', 'w'), 4),
(('d', 't'), 4),
(('j', 'd'), 4),
(('j', 'c'), 4),
(('y', 'w'), 4),
(('v', 'k'), 3),
(('x', 'w'), 3),
(('t', 'j'), 3),
(('c', 'j'), 3),
(('q', 'w'), 3),
(('g', 'b'), 3),
(('o', 'q'), 3),
(('r', 'x'), 3),
(('d', 'c'), 3),
(('g', 'j'), 3),
(('x', 'f'), 3),
(('z', 'w'), 3),
(('d', 'k'), 3),
(('u', 'u'), 3),
(('m', 'v'), 3),
(('c', 'x'), 3),
(('l', 'q'), 3),
(('p', 'b'), 2),
(('t', 'g'), 2),
(('q', 's'), 2),
(('t', 'x'), 2),
(('f', 'k'), 2),
(('b', 't'), 2),
(('j', 'n'), 2),
(('k', 'c'), 2),
(('z', 'k'), 2),
(('s', 'j'), 2),
(('s', 'f'), 2),
(('z', 'j'), 2),
(('n', 'q'), 2),
(('f', 'z'), 2),
(('h', 'g'), 2),
(('w', 'w'), 2),
(('k', 'j'), 2),
(('j', 'k'), 2),
(('w', 'm'), 2),
(('z', 'c'), 2),
(('z', 'v'), 2),
(('w', 'f'), 2),
(('q', 'm'), 2),
(('k', 'z'), 2),
(('j', 'j'), 2),
(('z', 'p'), 2),
(('j', 't'), 2),
(('k', 'b'), 2),
(('m', 'w'), 2),
(('h', 'f'), 2),
(('c', 'g'), 2),
(('t', 'f'), 2),
(('h', 'c'), 2),
(('q', 'o'), 2),
(('k', 'd'), 2),
(('k', 'v'), 2),
(('s', 'g'), 2),
(('z', 'd'), 2),
(('q', 'r'), 1),
(('d', 'z'), 1),
(('p', 'j'), 1),
(('q', 'l'), 1),
(('p', 'f'), 1),
(('q', 'e'), 1),
(('b', 'c'), 1),
(('c', 'd'), 1),
(('m', 'f'), 1),
(('p', 'n'), 1),
(('w', 'b'), 1),
(('p', 'c'), 1),
(('h', 'p'), 1),
(('f', 'h'), 1),
(('b', 'j'), 1),
(('f', 'g'), 1),
(('z', 'g'), 1),
(('c', 'p'), 1),
(('p', 'k'), 1),
(('p', 'm'), 1),
(('x', 'n'), 1),
(('s', 'q'), 1),
(('k', 'f'), 1),
(('m', 'k'), 1),
(('x', 'h'), 1),
(('g', 'f'), 1),
(('v', 'b'), 1),
(('j', 'p'), 1),
(('g', 'z'), 1),
(('v', 'd'), 1),
(('d', 'b'), 1),
(('v', 'h'), 1),
(('h', 'h'), 1),
(('g', 'v'), 1),
(('d', 'q'), 1),
(('x', 'b'), 1),
(('w', 'z'), 1),
(('h', 'q'), 1),
(('j', 'b'), 1),
(('x', 'm'), 1),
(('w', 'g'), 1),
(('t', 'b'), 1),
(('z', 'x'), 1)]
And this is the sorted list of counts of the individual bigrams across all the words in the dataset! Now let’s convert our current bigram-to-occurence-frequency map into a bigram counts array, where every row index represents the first character and every column index represents the second character of each bigram. Before doing so, we must first find a way to convert each character into a unique integer index:
chars = ["."] + sorted(list(set("".join(words))))
ctoi = {c: i for i, c in enumerate(chars)}
print(ctoi)
{'.': 0, 'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12, 'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17, 'r': 18, 's': 19, 't': 20, 'u': 21, 'v': 22, 'w': 23, 'x': 24, 'y': 25, 'z': 26}
Now that we have a character-to-index map, we may construct our bigram counts array N:
import torch
nchars = len(chars)
N = torch.zeros(nchars, nchars, dtype=torch.int32)
for w in words:
chs = ["."] + list(w) + ["."]
for ch1, ch2 in zip(chs, chs[1:]):
N[ctoi[ch1], ctoi[ch2]] += 1
N
tensor([[ 0, 4410, 1306, 1542, 1690, 1531, 417, 669, 874, 591, 2422, 2963,
1572, 2538, 1146, 394, 515, 92, 1639, 2055, 1308, 78, 376, 307,
134, 535, 929],
[6640, 556, 541, 470, 1042, 692, 134, 168, 2332, 1650, 175, 568,
2528, 1634, 5438, 63, 82, 60, 3264, 1118, 687, 381, 834, 161,
182, 2050, 435],
[ 114, 321, 38, 1, 65, 655, 0, 0, 41, 217, 1, 0,
103, 0, 4, 105, 0, 0, 842, 8, 2, 45, 0, 0,
0, 83, 0],
[ 97, 815, 0, 42, 1, 551, 0, 2, 664, 271, 3, 316,
116, 0, 0, 380, 1, 11, 76, 5, 35, 35, 0, 0,
3, 104, 4],
[ 516, 1303, 1, 3, 149, 1283, 5, 25, 118, 674, 9, 3,
60, 30, 31, 378, 0, 1, 424, 29, 4, 92, 17, 23,
0, 317, 1],
[3983, 679, 121, 153, 384, 1271, 82, 125, 152, 818, 55, 178,
3248, 769, 2675, 269, 83, 14, 1958, 861, 580, 69, 463, 50,
132, 1070, 181],
[ 80, 242, 0, 0, 0, 123, 44, 1, 1, 160, 0, 2,
20, 0, 4, 60, 0, 0, 114, 6, 18, 10, 0, 4,
0, 14, 2],
[ 108, 330, 3, 0, 19, 334, 1, 25, 360, 190, 3, 0,
32, 6, 27, 83, 0, 0, 201, 30, 31, 85, 1, 26,
0, 31, 1],
[2409, 2244, 8, 2, 24, 674, 2, 2, 1, 729, 9, 29,
185, 117, 138, 287, 1, 1, 204, 31, 71, 166, 39, 10,
0, 213, 20],
[2489, 2445, 110, 509, 440, 1653, 101, 428, 95, 82, 76, 445,
1345, 427, 2126, 588, 53, 52, 849, 1316, 541, 109, 269, 8,
89, 779, 277],
[ 71, 1473, 1, 4, 4, 440, 0, 0, 45, 119, 2, 2,
9, 5, 2, 479, 1, 0, 11, 7, 2, 202, 5, 6,
0, 10, 0],
[ 363, 1731, 2, 2, 2, 895, 1, 0, 307, 509, 2, 20,
139, 9, 26, 344, 0, 0, 109, 95, 17, 50, 2, 34,
0, 379, 2],
[1314, 2623, 52, 25, 138, 2921, 22, 6, 19, 2480, 6, 24,
1345, 60, 14, 692, 15, 3, 18, 94, 77, 324, 72, 16,
0, 1588, 10],
[ 516, 2590, 112, 51, 24, 818, 1, 0, 5, 1256, 7, 1,
5, 168, 20, 452, 38, 0, 97, 35, 4, 139, 3, 2,
0, 287, 11],
[6763, 2977, 8, 213, 704, 1359, 11, 273, 26, 1725, 44, 58,
195, 19, 1906, 496, 5, 2, 44, 278, 443, 96, 55, 11,
6, 465, 145],
[ 855, 149, 140, 114, 190, 132, 34, 44, 171, 69, 16, 68,
619, 261, 2411, 115, 95, 3, 1059, 504, 118, 275, 176, 114,
45, 103, 54],
[ 33, 209, 2, 1, 0, 197, 1, 0, 204, 61, 1, 1,
16, 1, 1, 59, 39, 0, 151, 16, 17, 4, 0, 0,
0, 12, 0],
[ 28, 13, 0, 0, 0, 1, 0, 0, 0, 13, 0, 0,
1, 2, 0, 2, 0, 0, 1, 2, 0, 206, 0, 3,
0, 0, 0],
[1377, 2356, 41, 99, 187, 1697, 9, 76, 121, 3033, 25, 90,
413, 162, 140, 869, 14, 16, 425, 190, 208, 252, 80, 21,
3, 773, 23],
[1169, 1201, 21, 60, 9, 884, 2, 2, 1285, 684, 2, 82,
279, 90, 24, 531, 51, 1, 55, 461, 765, 185, 14, 24,
0, 215, 10],
[ 483, 1027, 1, 17, 0, 716, 2, 2, 647, 532, 3, 0,
134, 4, 22, 667, 0, 0, 352, 35, 374, 78, 15, 11,
2, 341, 105],
[ 155, 163, 103, 103, 136, 169, 19, 47, 58, 121, 14, 93,
301, 154, 275, 10, 16, 10, 414, 474, 82, 3, 37, 86,
34, 13, 45],
[ 88, 642, 1, 0, 1, 568, 0, 0, 1, 911, 0, 3,
14, 0, 8, 153, 0, 0, 48, 0, 0, 7, 7, 0,
0, 121, 0],
[ 51, 280, 1, 0, 8, 149, 2, 1, 23, 148, 0, 6,
13, 2, 58, 36, 0, 0, 22, 20, 8, 25, 0, 2,
0, 73, 1],
[ 164, 103, 1, 4, 5, 36, 3, 0, 1, 102, 0, 0,
39, 1, 1, 41, 0, 0, 0, 31, 70, 5, 0, 3,
38, 30, 19],
[2007, 2143, 27, 115, 272, 301, 12, 30, 22, 192, 23, 86,
1104, 148, 1826, 271, 15, 6, 291, 401, 104, 141, 106, 4,
28, 23, 78],
[ 160, 860, 4, 2, 2, 373, 0, 1, 43, 364, 2, 2,
123, 35, 4, 110, 2, 0, 32, 4, 4, 73, 2, 3,
1, 147, 45]], dtype=torch.int32)
Done! Of course, this looks like a mess. So let’s visualize it better.
import matplotlib.pyplot as plt
if IN_COLAB:
%matplotlib inline
else:
%matplotlib ipympl
itoc = {i: c for c, i in ctoi.items()}
plt.figure(figsize=(16, 16))
plt.imshow(N, cmap="Blues")
for i in range(27):
for j in range(27):
chstr = itoc[i] + itoc[j]
plt.text(j, i, chstr, ha="center", va="bottom", color="gray")
plt.text(j, i, N[i, j].item(), ha="center", va="top", color="gray")
plt.axis("off")
(np.float64(-0.5), np.float64(26.5), np.float64(26.5), np.float64(-0.5))
The color-graded bigram counts array! Looks good. This array actually has all the necessary information for us to start sampling from this bigram character language model. Let’s just start by sampling the start character (of course) of each name: the . character. The first row tells us how often each other character follows it. In other words, the first row tells us how often each character is the first character of a word:
N[0]
tensor([ 0, 4410, 1306, 1542, 1690, 1531, 417, 669, 874, 591, 2422, 2963,
1572, 2538, 1146, 394, 515, 92, 1639, 2055, 1308, 78, 376, 307,
134, 535, 929], dtype=torch.int32)
To get the probability of each of character being the first:
p = N[0].float()
p = p / p.sum()
p
tensor([0.0000, 0.1377, 0.0408, 0.0481, 0.0528, 0.0478, 0.0130, 0.0209, 0.0273,
0.0184, 0.0756, 0.0925, 0.0491, 0.0792, 0.0358, 0.0123, 0.0161, 0.0029,
0.0512, 0.0642, 0.0408, 0.0024, 0.0117, 0.0096, 0.0042, 0.0167, 0.0290])
Each value of this probability distribution corresponds simply to the probability of the corresponding character being the first character of a word. And of course it sums to 1:
assert p.sum() == 1
Now, we’ll sample numbers according to this probability distribution using torch.multinomial. And to do so deterministically we are going to use a generator. So, let’s take a brief detour and test out how to sample. First we create a probability distribution:
SEED = 2147483647
g = torch.Generator().manual_seed(SEED)
ptest = torch.rand(3, generator=g)
ptest = ptest / ptest.sum()
ptest
tensor([0.6064, 0.3033, 0.0903])
Then, we sample from this distribution:
s = torch.multinomial(ptest, num_samples=100, replacement=True, generator=g)
s
tensor([1, 1, 2, 0, 0, 2, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 2, 0, 0,
1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1,
0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 1, 0, 0, 2, 0, 1, 0,
0, 1, 1, 1])
Simple. Now, notice that it outputs the same tensor however many times you run the cells. That’s because we have set a fixed seed and passed the generator object to the functions. Now, notice the output of torch.multinomial. What we expect is that around \(60.64\%\) of the numbers to be 0, \(30.33\%\) to be 1 and \(9.03\%\) to be 2:
sbc = torch.bincount(s)
for i in [0, 1, 2]:
print(f"Ratio of {i}: {sbc[i]/sbc.sum()}")
Ratio of 0: 0.6100000143051147
Ratio of 1: 0.33000001311302185
Ratio of 2: 0.05999999865889549
Not too far away from what we expected! But, if we increase the number of samples, we will get much closer to the probabilities of our distribution. Try it out! The more samples we take, the more the actual occurence ratios match the probabilities of the distribution the numbers were sampled from. Now, it’s time to sample from our initial character probability distribution:
g = torch.Generator().manual_seed(SEED)
idx = torch.multinomial(p, num_samples=1, replacement=True, generator=g).item()
itoc[idx]
'j'
We are now ready to write out our name generator.
g = torch.Generator().manual_seed(SEED)
P = N.float()
P = P / P.sum(
1, keepdim=True
) # sum over the column dimension and keep column dimension
for i in range(20):
out = []
idx = 0
while True:
p = P[idx]
idx = torch.multinomial(p, num_samples=1, replacement=True, generator=g).item()
out.append(itoc[idx])
if idx == 0:
break
print("".join(out))
junide.
janasah.
p.
cony.
a.
nn.
kohin.
tolian.
juee.
ksahnaauranilevias.
dedainrwieta.
ssonielylarte.
faveumerifontume.
phynslenaruani.
core.
yaenon.
ka.
jabdinerimikimaynin.
anaasn.
ssorionsush.
It works! It yields names. Well, kinda. Some look name-like enough but most are just terrible. Lol. This is a bigrams model for you! To recap, we trained a bigrams language model essentially just by counting how frequently any pairing of characters occurs and then normalizing so that we get a nice probability distribution. Really, the elements of array P are the parameters of our model that summarize the statistics of these bigrams. We train the model and iteratively sample the next character and feed it in each time and get the next character. But how do we evaluate our model? We can do so, by looking at the probability of each bigram.
for w in words[:3]:
chs = ["."] + list(w) + ["."]
for ch1, ch2 in zip(chs, chs[1:]):
ix1 = ctoi[ch1]
ix2 = ctoi[ch2]
prob = P[ix1, ix2]
print(f"{ch1}{ch2}: {prob:.4f}")
.e: 0.0478
em: 0.0377
mm: 0.0253
ma: 0.3899
a.: 0.1960
.o: 0.0123
ol: 0.0780
li: 0.1777
iv: 0.0152
vi: 0.3541
ia: 0.1381
a.: 0.1960
.a: 0.1377
av: 0.0246
va: 0.2495
a.: 0.1960
Here we are looking at the probabilities that the model assigns to every bigram in the dataset. Just keep in mind that we have \(27\) characters, so if everything was equally likely we would expect all probabilities to be:
1/27
0.037037037037037035
Since they are not and we have mostly higher probabilities, it means that our model has learned something useful. In an ideal case, we would expect the bigram probabilities to be near \(1.0\) (perfect prediction probability). Now, when you look at the literature of maximum likelihood estimation, statistical modelling and so on, you’ll see that what’s typically used here is something called the likelihood: the product of all the above probabilities. This gives us the probability of the entire dataset assigned by the model that you made. But, because the product of these probabilities is an unwieldly, very tiny number to work with (think \(0.0478 \times 0.0377 \times 0.0253 \times ...\)), for convenience, what people usually work with is not the likelihood, but the log-likelihood. The log, as you can see:
import numpy as np
x = np.arange(0.01, 1.0, 0.01)
y = np.log(x)
plt.figure()
plt.plot(x, y)
[<matplotlib.lines.Line2D at 0x7f6a401776d0>]
is a monotonic transformation of the probability, where if you pass in probability \(1.0\) you get log-probability of \(0\), and as the probabilities you pass in decrease, the log-probability decreases all the way to \(-\infty\) as the probability approaches \(0\). Therefore, let’s also add the log probability in our loop to see what that looks like:
def test_model(iterable, print_probs=True, calc_ll=False, print_nll=False):
if print_nll:
calc_ll = True
log_likelihood = 0.0
n = 0
for w in iterable:
chs = ["."] + list(w) + ["."]
for ch1, ch2 in zip(chs, chs[1:]):
prob = P[ctoi[ch1], ctoi[ch2]]
logprob = torch.log(prob)
if calc_ll:
log_likelihood += logprob.item()
n += 1
if print_probs:
print(f"{ch1}{ch2}: {prob:.4f} {logprob:.4f}")
if calc_ll:
print(f"{log_likelihood=}")
if print_nll:
nll = -log_likelihood
print(f"{nll=}")
print(f"loss={nll/n}")
return log_likelihood
_ = test_model(words[:3])
.e: 0.0478 -3.0408
em: 0.0377 -3.2793
mm: 0.0253 -3.6772
ma: 0.3899 -0.9418
a.: 0.1960 -1.6299
.o: 0.0123 -4.3982
ol: 0.0780 -2.5508
li: 0.1777 -1.7278
iv: 0.0152 -4.1867
vi: 0.3541 -1.0383
ia: 0.1381 -1.9796
a.: 0.1960 -1.6299
.a: 0.1377 -1.9829
av: 0.0246 -3.7045
va: 0.2495 -1.3882
a.: 0.1960 -1.6299
As you can see, for higher probabilities we get closer and closer to \(0\), but lower probabilities gives us a more negative number. And so to calculate the log-likelihood, we just sum up all the log probabilities:
log_likelihood = test_model(words[:3], calc_ll=True)
.e: 0.0478 -3.0408
em: 0.0377 -3.2793
mm: 0.0253 -3.6772
ma: 0.3899 -0.9418
a.: 0.1960 -1.6299
.o: 0.0123 -4.3982
ol: 0.0780 -2.5508
li: 0.1777 -1.7278
iv: 0.0152 -4.1867
vi: 0.3541 -1.0383
ia: 0.1381 -1.9796
a.: 0.1960 -1.6299
.a: 0.1377 -1.9829
av: 0.0246 -3.7045
va: 0.2495 -1.3882
a.: 0.1960 -1.6299
log_likelihood=-38.785636603832245
Now, how high can log-likelihood get? As high as \(0\)! So, when all the probabilities are \(1.0\), it will be \(0\). But the further away from \(1.0\) they are, the more negative the log-likehood will get. Now, we don’t actually like this because we are looking to define here is a loss function, that has the semantics where high is bad and low is good, since we are trying to minimize it. Any ideas? Well, we actually just need to invert the log-likelihood, aka take the negative log-likelihood (nll):
nll = -log_likelihood
print(f'{nll=}')
nll=38.785636603832245
nll is a very nice loss function because the lowest it can get is zero and the higher it is the worse off the predictions are that we are making. People also usually like to see the average of the nll instead of just the sum:
test_model(words[:3], print_probs=False, calc_ll=True, print_nll=True);
log_likelihood=-38.785636603832245
nll=38.785636603832245
loss=2.4241022877395153
Our loss function for the training set assigned by the model yields a loss of \(2.424\). The lower it is, the better off we are. The higher it is, the worse off we are. So, the job of training is produce a high-quality model, by finding the parameters that minimize the loss. In this case, ones that minimize the nll loss. To summarize, our goal is to maximize likelihood of the data w.r.t. model parameters (in our statistical modeling case these are the bigram probabilities), which is:
equivalent to maximizing the log-likelihood (because the \(\log\) function is monotonic)
equivalent to minimizing the nll
equivalent to minimizing the average nll
The lower the nll loss the better, since that would mean assigning high probabilities. Remember: \(\log(a \cdot b \cdot c) = \log(a) + \log(b) + \log(c)\). Also, keep in mind that here we store the probabilities in a table format. But in what’s coming up, these numbers will not be kept explicitly but they will be calculated by a nn and we will change its parameters to maximize the likelihood of these probabilities. Let’s now test out our model with a random name:
test_model(iterable=['christosqj'], calc_ll=True, print_nll=True);
.c: 0.0481 -3.0337
ch: 0.1880 -1.6713
hr: 0.0268 -3.6199
ri: 0.2388 -1.4320
is: 0.0743 -2.5990
st: 0.0944 -2.3605
to: 0.1197 -2.1224
os: 0.0635 -2.7563
sq: 0.0001 -9.0004
qj: 0.0000 -inf
j.: 0.0245 -3.7098
log_likelihood=-inf
nll=inf
loss=inf
As you can see, the probability of the bigram sq is super low. Whereas the probability for qj, since it is never encountered in our training data (see our bigram count table!), is \(0\), which predictably yields a log-probability of \(-\infty\), which in turn causes the loss to be \(-\infty\). What this means is that this model is exactly \(0 \%\) likely to predict this name (infinite loss). If you look up the table you see that q is followed by j zero times. This kind of behavior people don’t usually like too much, so there is a simple trick to alleviate it: model smoothing. It involves adding some fake counts to the bigram counts array so that never is there a bigram with 0 counts (and therefore 0 probability). This ensures that there are no zeros in our bigram counts matrix. E.g.
P = (N + 1).float()
P = P / P.sum(
1, keepdim=True
) # sum over the column dimension and keep column dimension
test_model(iterable=["christosqj"], calc_ll=True, print_nll=True)
.c: 0.0481 -3.0339
ch: 0.1869 -1.6774
hr: 0.0268 -3.6185
ri: 0.2384 -1.4338
is: 0.0743 -2.5998
st: 0.0942 -2.3625
to: 0.1193 -2.1257
os: 0.0634 -2.7578
sq: 0.0002 -8.3105
qj: 0.0033 -5.7004
j.: 0.0246 -3.7051
log_likelihood=-37.32549834251404
nll=37.32549834251404
loss=3.393227122046731
-37.32549834251404
Now, we avoid getting a loss of \(-\infty\). Cool! So we’ve now trained a respectable bigram character-level language model. We trained the model by looking at the counts of all the bigrams and normalizing the rows to get probability distributions. We saw that we can also then use those parameters of this model to perform sampling of new words (sample new names according to these distributions) and evaluate the quality of this model which is summarized by a single number: the nll. And the lower this number is, the better the model is because it is giving high probabilities to the actual mixed characters of all the bigrams in our training set. Great! We basically, counted and then normalized those counts, which is sensible enough.
Casting the model as a nn#
Let’s now try a different approach by casting such a bigram language model into a nn framework to achieve the same goal. Our nn is still going to be a bigram character-level language model. It will receive a single character as an input that will pass through a bunch of weighted neurons and then output the probability distribution over the next character in the sequence. It’s going to make guesses about what character is going to follow the input character. In addition, we’ll be able to evaluate any setting of the parameters of the nn, since we have a loss function. Basically, we’re going to take a look at the probabilities distributions our model assigns for our next character and find the loss between those and the labels (which are the character that we expect to come next in the bigram). By doing so, we can use gradient-based optimization to tune the weights of our nn that give us the output probabilities. Let’s begin this alternative approach by first constructing our dataset:
# Create training dataset of bigrams (x, y)
xs, ys = [], []
for w in words[:1]:
chs = ["."] + list(w) + ["."]
for ch1, ch2 in zip(chs, chs[1:]):
print(ch1, ch2)
xs.append(ctoi[ch1])
ys.append(ctoi[ch2])
# Convert to pytorch tensor (https://pytorch.org/docs/stable/generated/torch.tensor.html)
xs = torch.tensor(xs)
ys = torch.tensor(ys)
. e
e m
m m
m a
a .
xs
tensor([ 0, 5, 13, 13, 1])
ys
tensor([ 5, 13, 13, 1, 0])
Now, how do we pass each character into the nn? One-hot encoding! With this encoding, each integer is encoded with bits.
import torch.nn.functional as F
xenc = F.one_hot(xs, num_classes=27).float()
xenc
tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.]])
xenc.shape
torch.Size([5, 27])
plt.figure()
plt.imshow(xenc);
Let’s create our neuron:
W = torch.randn((27, 1))
xenc @ W
tensor([[-0.3270],
[-1.4539],
[-0.8739],
[-0.8739],
[ 1.4181]])
Our neuron receives one character of size \(27\) and spits out \(1\) output value. However, as you can see, since PyTorch supports matrix multiplication, our neuron can receive \(5\) characters of size \(27\) in parallel and output each character’s output in a \(5 \times 1\) matrix (\([5 \times 27] \cdot [27 \times 1] \rightarrow [5 \times 1]\)). Now, let’s pass our \(5\) characters as inputs through \(27\) neurons instead of just \(1\) neuron:
W = torch.randn((27, 27))
xenc @ W
tensor([[ 0.9979, 0.2825, 1.1355, 0.3798, -0.2801, 0.0672, -1.1496, 2.1393,
-0.2687, -1.4350, 1.1158, 0.4346, -0.4915, -0.1916, 1.4139, -0.4590,
-0.5869, 1.6688, 0.8819, 0.8542, -0.0366, -0.6968, 0.1041, 0.8881,
0.7592, -0.5573, 0.9596],
[-0.1725, -1.5476, 1.5005, 1.4560, 0.9079, -1.2025, 0.1265, 0.1533,
-0.2189, -1.3150, 1.6275, 0.3342, 1.4620, -0.3458, -0.2391, 0.5896,
1.7679, 1.1726, -0.6278, -0.1539, -0.6117, -0.0106, 0.7131, 2.0526,
1.2183, 1.6270, -1.3764],
[-1.0529, -0.4609, 0.6597, 0.5148, -1.1303, 0.5723, 0.1907, -0.1367,
0.3072, 1.2870, -2.0319, -0.2964, 0.3874, -1.2633, -1.3800, 1.4614,
0.2344, 0.1867, 0.0559, -2.1201, -0.7034, 0.7074, -0.5500, -1.3492,
0.1524, 1.5829, 0.3142],
[-1.0529, -0.4609, 0.6597, 0.5148, -1.1303, 0.5723, 0.1907, -0.1367,
0.3072, 1.2870, -2.0319, -0.2964, 0.3874, -1.2633, -1.3800, 1.4614,
0.2344, 0.1867, 0.0559, -2.1201, -0.7034, 0.7074, -0.5500, -1.3492,
0.1524, 1.5829, 0.3142],
[ 0.2948, 0.0746, -0.4187, 0.4092, -0.6537, 1.1562, 0.6917, -1.2596,
-0.1424, -0.5520, -1.1731, -0.4088, -0.6465, -0.2629, -0.3580, 0.8126,
-1.7589, 1.7377, -0.5665, 1.9188, -0.6135, -1.2176, 0.0166, 0.1594,
-0.8806, 0.6167, -0.9173]])
Predictably, we get \(5\) arrays (one per input/character) of \(27\) outputs (\([5 \times 27] \cdot [27 \times 27] \rightarrow [5 \times 27]\)). Each output number represents each neuron’s firing rate of a specific input. For example, the following is the firing rate of the 13th neuron of the 3rd input:
(xenc @ W)[3, 13]
tensor(-1.2633)
What PyTorch allows is matrix multiplication that enables parallel dot products of many inputs in a batch with the weights of neurons of a nn. For example, this is how to multiply the inputs that represent the 3rd character with the weights of the 13th neuron:
xenc[3]
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.])
W[:, 13]
tensor([-0.1916, -0.2629, -1.1183, 0.9108, 0.7797, -0.3458, -1.2783, -0.7899,
-0.3221, -0.4800, 0.3307, 0.2826, -0.5372, -1.2633, 0.3663, 0.1210,
0.0446, -0.1690, -0.3741, -0.0798, -0.5883, -0.9373, -0.1367, -0.2475,
-0.4424, -2.0253, -0.1943])
(xenc[3] * W[:, 13]).sum()
tensor(-1.2633)
(xenc @ W)[3, 13] # same as above
tensor(-1.2633)
Ok, so what did is we fed our \(27\)-dimensional inputs into the first layer of a nn that has 27 neurons. These neurons perform W * x. They don’t have a bias and they don’t have a non-linearity like tanh. We are going to leave our network as is: a 1-layer linear nn. That’s it. Basically, the dumbest, smallest, simplest nn. Remember, what we trying to produce is a probability distribution for a next character in a sequence. And there’s \(27\) of them. But we have to come up with exact semantics as to how we are going to interpret these \(27\) numbers that these neurons take on. Intuitively, as we can see in the xenc @ W output, some of these outputs numbers are positive and some negative. That’s because they come out of a nn layer with weights are initialized from the normal \([-1, 1]\) distribution. But, what we want however is something like a bigram count table that we previously produced, where each row told us the counts which we then normalized to get the probabilities. So, we want something similar to come out of our nn. But, what we have right now, are some negative and positive numbers. Now, we therefore want these numbers to represent the probabilities for the next character with their unique characteristics. For example, probabilities are positive numbers and they sum to 1. Also, they obviously have to be probabilities. They can’t be counts because counts are positive integers; not a great output from a nn. Instead, what the nn is going to output and how we are going to interpret these \(27\) output numbers is as log counts. One way to accomplish this is by exponentiating each output number so that the result is always positive. Specifically, exponentiating a negative number yields a result that is a positive value less than \(1\). Whereas, exponentiating a positive number yields a result whose value is between greater than \(1\) and \(\infty\).
(xenc @ W).exp()
tensor([[2.7125, 1.3265, 3.1128, 1.4619, 0.7557, 1.0695, 0.3168, 8.4932, 0.7644,
0.2381, 3.0519, 1.5444, 0.6117, 0.8256, 4.1119, 0.6319, 0.5561, 5.3059,
2.4156, 2.3495, 0.9641, 0.4982, 1.1098, 2.4304, 2.1365, 0.5727, 2.6108],
[0.8415, 0.2128, 4.4841, 4.2888, 2.4792, 0.3004, 1.1348, 1.1657, 0.8034,
0.2685, 5.0910, 1.3968, 4.3146, 0.7077, 0.7873, 1.8032, 5.8586, 3.2305,
0.5338, 0.8574, 0.5424, 0.9895, 2.0402, 7.7883, 3.3814, 5.0888, 0.2525],
[0.3489, 0.6307, 1.9343, 1.6733, 0.3229, 1.7724, 1.2100, 0.8722, 1.3596,
3.6221, 0.1311, 0.7435, 1.4731, 0.2827, 0.2516, 4.3118, 1.2641, 1.2053,
1.0575, 0.1200, 0.4949, 2.0286, 0.5769, 0.2595, 1.1647, 4.8691, 1.3691],
[0.3489, 0.6307, 1.9343, 1.6733, 0.3229, 1.7724, 1.2100, 0.8722, 1.3596,
3.6221, 0.1311, 0.7435, 1.4731, 0.2827, 0.2516, 4.3118, 1.2641, 1.2053,
1.0575, 0.1200, 0.4949, 2.0286, 0.5769, 0.2595, 1.1647, 4.8691, 1.3691],
[1.3429, 1.0774, 0.6579, 1.5056, 0.5201, 3.1778, 1.9972, 0.2838, 0.8673,
0.5758, 0.3094, 0.6644, 0.5239, 0.7688, 0.6990, 2.2538, 0.1722, 5.6841,
0.5675, 6.8131, 0.5415, 0.2959, 1.0168, 1.1728, 0.4145, 1.8528, 0.3996]])
Such exponentiation is a great way to make the nn predict counts. Which are positive numbers that can take on various values depending on the setting of W. Let’s break it down more:
logits = xenc @ W # log-counts
counts = logits.exp() # equivalent to the N bigram counts array
probs = counts / counts.sum(1, keepdims=True)
probs
tensor([[0.0522, 0.0255, 0.0599, 0.0281, 0.0145, 0.0206, 0.0061, 0.1634, 0.0147,
0.0046, 0.0587, 0.0297, 0.0118, 0.0159, 0.0791, 0.0122, 0.0107, 0.1021,
0.0465, 0.0452, 0.0185, 0.0096, 0.0214, 0.0468, 0.0411, 0.0110, 0.0502],
[0.0139, 0.0035, 0.0739, 0.0707, 0.0409, 0.0050, 0.0187, 0.0192, 0.0132,
0.0044, 0.0840, 0.0230, 0.0711, 0.0117, 0.0130, 0.0297, 0.0966, 0.0533,
0.0088, 0.0141, 0.0089, 0.0163, 0.0336, 0.1284, 0.0558, 0.0839, 0.0042],
[0.0099, 0.0178, 0.0547, 0.0473, 0.0091, 0.0501, 0.0342, 0.0247, 0.0385,
0.1025, 0.0037, 0.0210, 0.0417, 0.0080, 0.0071, 0.1220, 0.0358, 0.0341,
0.0299, 0.0034, 0.0140, 0.0574, 0.0163, 0.0073, 0.0329, 0.1377, 0.0387],
[0.0099, 0.0178, 0.0547, 0.0473, 0.0091, 0.0501, 0.0342, 0.0247, 0.0385,
0.1025, 0.0037, 0.0210, 0.0417, 0.0080, 0.0071, 0.1220, 0.0358, 0.0341,
0.0299, 0.0034, 0.0140, 0.0574, 0.0163, 0.0073, 0.0329, 0.1377, 0.0387],
[0.0371, 0.0298, 0.0182, 0.0416, 0.0144, 0.0879, 0.0552, 0.0078, 0.0240,
0.0159, 0.0086, 0.0184, 0.0145, 0.0213, 0.0193, 0.0623, 0.0048, 0.1572,
0.0157, 0.1884, 0.0150, 0.0082, 0.0281, 0.0324, 0.0115, 0.0512, 0.0111]])
Therefore, we have a way to get the probabilities, where each row sums to \(1\) (since they are normalized), e.g.
probs[0].sum().item()
1.0
probs.shape
torch.Size([5, 27])
What we have achieved is that for every one of our \(5\) examples, we now have a row that came out of our nn. And because of the transformations here, we made sure that this output of the nn can be interpreted as probabilities. In other words, what we have done is that we took inputs, applied differentiable operations on them (e.g. @, exp()) that we can backprop through and we are getting out probability distributions. Take the first input character that was fed in as an example:
xenc[0]
tensor([1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.])
that corresponds to the . symbol from the name:
words[0]
'emma'
The way we fed this character into the neural network is that we first got its index, then we one-hot encoded it, then it went into the nn and out came this distribution of probabilities:
probs[0]
tensor([0.0522, 0.0255, 0.0599, 0.0281, 0.0145, 0.0206, 0.0061, 0.1634, 0.0147,
0.0046, 0.0587, 0.0297, 0.0118, 0.0159, 0.0791, 0.0122, 0.0107, 0.1021,
0.0465, 0.0452, 0.0185, 0.0096, 0.0214, 0.0468, 0.0411, 0.0110, 0.0502])
with a shape of:
probs[0].shape
torch.Size([27])
\(27\) numbers. We interpret these numbers of probs[0] as the probability or how likely it is for each of the corresponding characters to come next. As we train the nn by tuning the weights W, we are of course going to be getting different probabilities out for every character that you input. So, the question is: can we tune W such that the probabilities coming out are pretty good? The way we measure pretty good is by the loss function. Below you can see what have done in a simple summary:
# SUMMARY ------------------------------>>>>
xs # inputs
tensor([ 0, 5, 13, 13, 1])
ys # targets
tensor([ 5, 13, 13, 1, 0])
Both xs and ys constitute the dataset. They are integers representing characters of a sequence/word.
# Use a generator for reproducability and randomly initialize 27 neurons' weights. Each neuron receives 27 inputs.
g = torch.Generator().manual_seed(SEED)
W = torch.randn((27, 27), generator=g) # 27 incoming weights for 27 neurons
# Encode the inputs into one-hot representations
xenc = F.one_hot(xs, num_classes=27).float() # input to the network: one-hot encoding
# Pass encoded inputs through first layer to get logits
logits = xenc @ W # predict log-counts
# Exponentiate the logits to get fake counts
counts = logits.exp() # counts, equivalent to N
# Normalize these counts to get probabilities
probs = counts / counts.sum(1, keepdims=True) # probabilities for next character
# NOTE: the 2 lines above constitute what is called a 'softmax'
probs.shape
torch.Size([5, 27])
Softmax is a very-often-used loss function in nns. It takes in logits, exponentiates them, then divides and normalizes. It’s a way of taking outputs of a linear layer that might be positive or negative and it outputs numbers that are only positive and always sum to \(1\), adhering to the properties of probability distributions. It can be viewed as a normalization function if you want to think of it that way.
from IPython.display import Image, display
display(Image(filename='softmax.jpeg'))
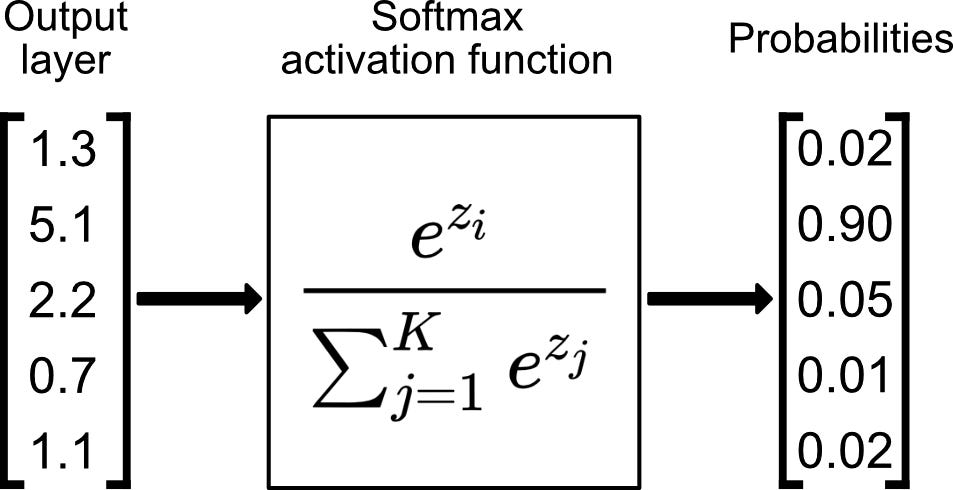
Now, since every operation in the forward pass is differentiable, we can backprop through. Below, we iterate over every input character and describe what is going on:
nlls = torch.zeros(5)
for i in range(5):
# i-th bigram:
x = xs[i].item() # input character index
y = ys[i].item() # label character index
print("--------")
print(f"bigram example {i+1}: {itoc[x]}{itoc[y]} (indexes {x},{y})")
print("input to the nn:", x)
print("output probabilities from the nn:", probs[i])
print("label (actual next character):", y)
p = probs[i, y]
print("probability assigned by the nn to the correct next character:", p.item())
logp = torch.log(p)
print("log likelihood:", logp.item())
nll = -logp
print("negative log likelihood:", nll.item())
nlls[i] = nll
loss = nlls.mean()
print("=========")
print("average negative log likelihood, i.e. loss =", loss.item())
--------
bigram example 1: .e (indexes 0,5)
input to the nn: 0
output probabilities from the nn: tensor([0.0607, 0.0100, 0.0123, 0.0042, 0.0168, 0.0123, 0.0027, 0.0232, 0.0137,
0.0313, 0.0079, 0.0278, 0.0091, 0.0082, 0.0500, 0.2378, 0.0603, 0.0025,
0.0249, 0.0055, 0.0339, 0.0109, 0.0029, 0.0198, 0.0118, 0.1537, 0.1459])
label (actual next character): 5
probability assigned by the nn to the correct next character: 0.01228625513613224
log likelihood: -4.399273872375488
negative log likelihood: 4.399273872375488
--------
bigram example 2: em (indexes 5,13)
input to the nn: 5
output probabilities from the nn: tensor([0.0290, 0.0796, 0.0248, 0.0521, 0.1989, 0.0289, 0.0094, 0.0335, 0.0097,
0.0301, 0.0702, 0.0228, 0.0115, 0.0181, 0.0108, 0.0315, 0.0291, 0.0045,
0.0916, 0.0215, 0.0486, 0.0300, 0.0501, 0.0027, 0.0118, 0.0022, 0.0472])
label (actual next character): 13
probability assigned by the nn to the correct next character: 0.018050700426101685
log likelihood: -4.014570713043213
negative log likelihood: 4.014570713043213
--------
bigram example 3: mm (indexes 13,13)
input to the nn: 13
output probabilities from the nn: tensor([0.0312, 0.0737, 0.0484, 0.0333, 0.0674, 0.0200, 0.0263, 0.0249, 0.1226,
0.0164, 0.0075, 0.0789, 0.0131, 0.0267, 0.0147, 0.0112, 0.0585, 0.0121,
0.0650, 0.0058, 0.0208, 0.0078, 0.0133, 0.0203, 0.1204, 0.0469, 0.0126])
label (actual next character): 13
probability assigned by the nn to the correct next character: 0.026691533625125885
log likelihood: -3.623408794403076
negative log likelihood: 3.623408794403076
--------
bigram example 4: ma (indexes 13,1)
input to the nn: 13
output probabilities from the nn: tensor([0.0312, 0.0737, 0.0484, 0.0333, 0.0674, 0.0200, 0.0263, 0.0249, 0.1226,
0.0164, 0.0075, 0.0789, 0.0131, 0.0267, 0.0147, 0.0112, 0.0585, 0.0121,
0.0650, 0.0058, 0.0208, 0.0078, 0.0133, 0.0203, 0.1204, 0.0469, 0.0126])
label (actual next character): 1
probability assigned by the nn to the correct next character: 0.07367686182260513
log likelihood: -2.6080665588378906
negative log likelihood: 2.6080665588378906
--------
bigram example 5: a. (indexes 1,0)
input to the nn: 1
output probabilities from the nn: tensor([0.0150, 0.0086, 0.0396, 0.0100, 0.0606, 0.0308, 0.1084, 0.0131, 0.0125,
0.0048, 0.1024, 0.0086, 0.0988, 0.0112, 0.0232, 0.0207, 0.0408, 0.0078,
0.0899, 0.0531, 0.0463, 0.0309, 0.0051, 0.0329, 0.0654, 0.0503, 0.0091])
label (actual next character): 0
probability assigned by the nn to the correct next character: 0.014977526850998402
log likelihood: -4.201204299926758
negative log likelihood: 4.201204299926758
=========
average negative log likelihood, i.e. loss = 3.7693049907684326
As you can see, the probabilities assigned by the nn to the correct next character are bad (pretty low). See for example the probability predicted by the network of m following e (em example): the nll value is very high (e.g. \(4.0145\)). And in general, for the whole word, the loss (the average nll) is high! This means that this is not a favorable setting of weights and we can do better. One easy way to do better is to reinitialize W using a different seed for example and pray to god that the loss is smaller or repeat until it is. But that is what amateurs do. We are professionals or, at least, we want to be! And what professionals do is they start with random weights, like we did, and then they optimize those weights in order to minimize the loss. We do so by some gradient-based optimization (e.g. gradient descent) which entails first doing backprop in order to compute the gradients of that weight w.r.t. to those weights and then changing the weights by some such gradient amount in order to optimize them and minimize the loss. As we did with micrograd, we will write an optimization loop for doing the backward pass. But instead of mean-squared error, we are using the nll as a loss function, since we are dealing with a classification task and not a regression one.
g = torch.Generator().manual_seed(SEED)
W = torch.randn(
(27, 27), generator=g, requires_grad=True
) # 27 incoming weights for 27 neurons
def forward_pass(regularize=False):
num = xs.nelement()
xenc = F.one_hot(
xs, num_classes=27
).float() # input to the network: one-hot encoding
logits = xenc @ W # predict log-counts
counts = logits.exp() # counts, equivalent to N
probs = counts / counts.sum(1, keepdims=True) # probabilities for next character
loss = -probs[torch.arange(num), ys].log().mean()
return W, loss
W, loss = forward_pass()
# backward pass
W.grad = None # set to zero
loss.backward()
Now, something magical happened when backward ran. Like micrograd, PyTorch, during the forward pass, keeps track of all the operations under the hood and builds a full computational graph. So, it knows all the dependencies and all the mathematical operations of everything. Therefore, calling backward on the loss fills in the gradients of all the intermediate nodes, all the way back to the W value nodes. Take a look:
W.grad
tensor([[ 0.0121, 0.0020, 0.0025, 0.0008, 0.0034, -0.1975, 0.0005, 0.0046,
0.0027, 0.0063, 0.0016, 0.0056, 0.0018, 0.0016, 0.0100, 0.0476,
0.0121, 0.0005, 0.0050, 0.0011, 0.0068, 0.0022, 0.0006, 0.0040,
0.0024, 0.0307, 0.0292],
[-0.1970, 0.0017, 0.0079, 0.0020, 0.0121, 0.0062, 0.0217, 0.0026,
0.0025, 0.0010, 0.0205, 0.0017, 0.0198, 0.0022, 0.0046, 0.0041,
0.0082, 0.0016, 0.0180, 0.0106, 0.0093, 0.0062, 0.0010, 0.0066,
0.0131, 0.0101, 0.0018],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0058, 0.0159, 0.0050, 0.0104, 0.0398, 0.0058, 0.0019, 0.0067,
0.0019, 0.0060, 0.0140, 0.0046, 0.0023, -0.1964, 0.0022, 0.0063,
0.0058, 0.0009, 0.0183, 0.0043, 0.0097, 0.0060, 0.0100, 0.0005,
0.0024, 0.0004, 0.0094],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0125, -0.1705, 0.0194, 0.0133, 0.0270, 0.0080, 0.0105, 0.0100,
0.0490, 0.0066, 0.0030, 0.0316, 0.0052, -0.1893, 0.0059, 0.0045,
0.0234, 0.0049, 0.0260, 0.0023, 0.0083, 0.0031, 0.0053, 0.0081,
0.0482, 0.0187, 0.0051],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000]])
And obviously:
assert W.shape == W.grad.shape
What a gradient value is telling us, e.g.
W.grad[1][4].item()
0.012119228951632977
is that nudging the specific corresponding weight by a small h value, would nudge the loss by that gradient amount. Since we want to decrease the loss, we simply need to change the weights by a small negative fraction of the gradients in order to move them in the direction that locally most steeply decreases the loss value:
W.data += -0.1 * W.grad
We just did a single gradient descent optimization step, which means that if we re-calculate the loss, it will be lower:
W, loss = forward_pass()
loss.item()
3.7492127418518066
Tada! All we have to do now is put everything together and stick the single step into a loop so that we can do multi-step gradient descent optimization. This time, for all the words in our dataset, not just emma!
# create the dataset
xs, ys = [], []
for w in words:
chs = ["."] + list(w) + ["."]
for ch1, ch2 in zip(chs, chs[1:]):
xs.append(ctoi[ch1])
ys.append(ctoi[ch2])
xs = torch.tensor(xs)
ys = torch.tensor(ys)
num = xs.nelement()
print("number of examples (bigrams): ", num)
# initialize the 'network'
g = torch.Generator().manual_seed(SEED)
W = torch.randn((27, 27), generator=g, requires_grad=True)
number of examples (bigrams): 228146
# gradient descent
for k in range(100):
W, loss = forward_pass()
print(loss.item())
# backward pass
W.grad = None # set to zero the gradient
loss.backward()
# update
W.data += -50 * W.grad
3.758953809738159
3.371098756790161
3.1540417671203613
3.020373821258545
2.9277119636535645
2.860402822494507
2.8097293376922607
2.7701027393341064
2.7380733489990234
2.711496591567993
2.6890034675598145
2.6696884632110596
2.6529300212860107
2.638277292251587
2.6253881454467773
2.6139907836914062
2.603863477706909
2.5948219299316406
2.586712121963501
2.57940411567688
2.572789192199707
2.5667762756347656
2.5612881183624268
2.5562589168548584
2.551633596420288
2.547365665435791
2.5434155464172363
2.539748430252075
2.5363364219665527
2.5331544876098633
2.5301806926727295
2.5273969173431396
2.5247862339019775
2.522334575653076
2.520029067993164
2.517857789993286
2.515810966491699
2.513878345489502
2.512052059173584
2.510324001312256
2.5086867809295654
2.5071346759796143
2.5056610107421875
2.5042612552642822
2.502929210662842
2.5016613006591797
2.5004522800445557
2.4992990493774414
2.498197317123413
2.497144937515259
2.496137857437134
2.495173692703247
2.4942495822906494
2.493363380432129
2.4925124645233154
2.4916954040527344
2.4909095764160156
2.4901540279388428
2.4894261360168457
2.488725185394287
2.4880495071411133
2.4873974323272705
2.4867680072784424
2.4861605167388916
2.4855728149414062
2.4850049018859863
2.484455108642578
2.4839231967926025
2.483408212661743
2.4829084873199463
2.482424020767212
2.481955051422119
2.481499195098877
2.4810571670532227
2.4806275367736816
2.480210304260254
2.479804754257202
2.479410171508789
2.4790265560150146
2.4786536693573
2.478290557861328
2.4779367446899414
2.477592706680298
2.477257251739502
2.4769301414489746
2.476611852645874
2.4763011932373047
2.4759981632232666
2.4757025241851807
2.475414276123047
2.475132703781128
2.474858045578003
2.4745893478393555
2.474327802658081
2.474071741104126
2.4738216400146484
2.4735770225524902
2.4733383655548096
2.47310471534729
2.47287654876709
Awesome! What we least expect is that our loss, by using such gradient-based optimization, becomes as small as the loss we got by our more primitive bigram-count-matrix way that we previously employed for optimizing. So, basically, before, we achieved roughly the same loss just by counting, whereas now we used gradient descent. It just happens that the explicit, counting approach nicely optimizes the model without the need for any gradient-based optimization because the setup for bigram language models is so straightforward and simple that we can afford to just directly estimate the probabilities and keep them in a table. However, the nn approach is much more flexible and scalable! And we have actually gained a lot. What we can do from hereon is expand and complexify our approach. Meaning, that instead of just taking a single character and predicting the next one in an extremely simple nn, as we have done so far, we will be taking multiple previous characters and we will be feeding them into increasingly more complex nns. But, fundamentally, we will still be just calculating logits that will be going through exactly the same transformation by passing them through a softmax and doing the same gradient-based optimization process we just did. But before we do that, remember the smoothing we did by adding fake counts to our bigram count matrix? Turns out, we can do equivalent smoothing in our nn too! In particular, just incentivizing the weights to be zero for example leads to the probabilities being uniform, which is a form of smoothing. Such incentivization can be accomplished through regularization. It involves just adding a term like this:
(W**2).mean()
tensor(1.6880, grad_fn=<MeanBackward0>)
to the loss as such:
loss = -probs[torch.arange(num), ys].log().mean() + 0.01 * (W**2).mean()
where 0.01 represents the strength of the regulatization term. Optimizing with this term included in the loss would smoothen the model. Yay! Lastly, let’s sample from our nn:
g = torch.Generator().manual_seed(SEED)
for i in range(20):
out = []
ix = 0
while True:
xenc = F.one_hot(torch.tensor([ix]), num_classes=27).float()
logits = xenc @ W # predict log-counts
counts = logits.exp() # counts, equivalent to N
probs = counts / counts.sum(1, keepdims=True) # probabilities for next character
# sample from probabilities distribution
ix = torch.multinomial(probs, num_samples=1, replacement=True, generator=g).item()
out.append(itoc[ix])
if ix == 0:
break
print(''.join(out))
junide.
janasah.
p.
cfay.
a.
nn.
kohin.
tolian.
juwe.
kilanaauranilevias.
dedainrwieta.
ssonielylarte.
faveumerifontume.
phynslenaruani.
core.
yaenon.
ka.
jabi.
werimikimaynin.
anaasn.
We are getting kind of the same results as we previously did with our counting method! Not unpredictable at all, since our loss values are close enough. If we trained our nn more and the loss values became the same, it would means that the two models are identical. Meaning that given the same inputs, they would spit out the same outputs.
Summary#
All in all, we have actually covered lots of ground. To sum up, we introduced the bigram character language model, we saw how we can train the model, how we can sample from the model and how we can evaluate the quality of the model using the nll loss. We actually trained the model in two completely different ways that actually give or can give (with adequate training) the same result. In the first way, we just counted up the frequency of all the bigrams and normalized. Whereas, in the second way, we used the nll loss as a guide to optimizing the counts matrix or the counts array, so that the loss is minimized in a gradient-based framework. Despite our nn being super simple (single linear layer), it is the more flexible approach.
Outro#
In the follow-up lessons, we are going to complexify by taking more and more of these characters and we are going to be feeding them into a new nn that does more exciting stuff. Buckle up!