1. micrograd: implementing an autograd engine#
import sys
IN_COLAB = "google.colab" in sys.modules
if IN_COLAB:
print("Cloning repo...")
!git clone --quiet https://github.com/ckaraneen/micrograduate.git > /dev/null
%cd micrograduate
print("Installing requirements...")
!pip install --quiet uv
!uv pip install --system --quiet -r requirements.txt
Intro#
Welcome! Let’s begin by implementing micrograd: an autograd engine. autograd stands for automatic gradient computation/differentiation and it is a feature that facilitates the backpropagation algorithm (backprop), enabling efficient calculation the gradient of an error or loss function w.r.t. (w.r.t.) the weights and biases of a neural network (nn). This allows us to iteratively tune these parameters, minimize the loss and therefore improve the accuracy of the network. backprop is at the mathematical core of any modern deep neural network library, like PyTorch or jax. micrograd’s functionality is best illustrated by an example.
Sneak peek#
from micrograd.engine import Value
a = Value(-4.0)
b = Value(2.0)
c = a + b
d = a * b + b**3
c += c + 1
c += 1 + c + (-a)
d += d * 2 + (b + a).relu()
d += 3 * d + (b - a).relu()
e = c - d
f = e**2
g = f / 2.0
g += 10.0 / f
print(f"{g.data:.4f}, the outcome of this forward pass")
g.backward()
print(f"{a.grad:.4f}, i.e. the numerical value of dg/da")
print(f"{b.grad:.4f}, i.e. the numerical value of dg/db")
24.7041, the outcome of this forward pass
138.8338, i.e. the numerical value of dg/da
645.5773, i.e. the numerical value of dg/db
You’ll see that micrograd allows us to build out mathematical expressions. Here, we have an expression that we’re building out where you have two inputs a and b whose values have been wrapped into a Value object. In this example, we build a mathematical expression graph. a and b are transformed into c and d, and eventually into e, f and g through some intermediary operations such as + (addition), * (multiplication) and exponentiation to a constant power (e.g. b**3). Other operations include offsetting by one, negation, squashing at zero, squaring, division, etc. And so from these values micrograd will, in the background, build out a mathematical expression graph. It will know, for example, that c is also a value but also a result of the addition operation of two child value nodes a and b, to which it will maintain pointers. So, we’ll basically know exactly how all this operations graph is laid out. Then, we can do a forward pass (a, b -> … -> g), but also initiate the backward pass that constitutes backprop by calling backward at node g: g.backward(). What backprop is going to do is start at g and it’s going to go backwards through that expression graph and it’s going to recursively apply the chain rule from calculus. This allows it to evaluate the derivative of g w.r.t. all the internal nodes, like e, d and c (i.e. \(\dfrac{\partial g}{\partial e}\), \(\dfrac{\partial g}{\partial d}\), \(\dfrac{\partial g}{\partial c}\)), but also w.r.t. the inputs a and b (i.e. \(\dfrac{\partial g}{\partial a}\), \(\dfrac{\partial g}{\partial b}\)). Then we can actually query this derivative of g w.r.t., for example, a (\(\dfrac{\partial g}{\partial a}\)) as such: a.grad, or the derivative of g w.r.t. b (\(\dfrac{\partial g}{\partial b}\)) as such: b.grad. The values of these grad attributes tell us how a tiny change of the values of a and b is affecting g. If we slightly nudge a and make it slightly larger, a.grad == 138.8338 is telling us that g will grow and that the slope of that growth is going to be equal to that number. Similarly, the slope of the growth of g w.r.t. a slight positive nudge of b is going to be \(645.5773\). A nn is a function that takes in inputs and weights and returns an output: \(F(in, w) = out\). micrograd will help you understand nns at such a fundamental level by disregarding non-essential elements (e.g. tensors) that you would otherwise encounter in practice, production, etc. micrograd is all you need in order to understand the basics. Everything else is just efficiency. Now, let’s dive right in and start implementing!
First, we must make sure that we develop a very good, intuitive understanding of what a derivative is and exactly what information it gives us.
import math
import numpy as np
import matplotlib.pyplot as plt
if IN_COLAB:
%matplotlib inline
else:
%matplotlib ipympl
def y(x):
return 3 * x**2 - 4 * x + 5
y(3.0)
20.0
xs = np.arange(-5, 5, 0.25)
ys = y(xs)
plt.figure()
plt.plot(xs, ys);
Above, we plotted a parabola. Now, to think through what the derivative of this function at any point x is let’s look up the definition of what it means for a function to be differentiable. Understanding the derivative boils down to finding how a such a function f responds to a slight nudge of its input x by a small number h. Meaning, with what sensitivity does it respond? Does the value go up or down? Or, to be more precise, what is the slope at that point x? Is it positive or negative? This exact amount we are looking for is given to us by the limit equation that we can very simply approximate numerically with a small enough h value, as follows.
h = 0.00000001
x = 3.0 # try -3.0, 2/3, etc.
(y(x + h) - y(x)) / h
14.00000009255109
Now, with a more complex example, to start building an intuition about the derivative, let’s find out the derivatives of d w.r.t. a, b and c (i.e. \(\dfrac{\partial d}{\partial a}\), \(\dfrac{\partial d}{\partial b}\), \(\dfrac{\partial d}{\partial c}\)).
h = 0.00000000000001
a = 2.0
b = -3.0
c = 10.0
d1 = a * b + c
a += h # try nudging `b` or `c` instead to see what happens
d2 = a * b + c
print(f"d1: {d1}")
print(f"d2: {d2}")
print(f"slope: {(d2 - d1)/h}")
d1: 4.0
d2: 3.99999999999997
slope: -3.019806626980426
We now have some intuitive sense of what a derivative is telling us about a function. So now let’s move unto nns, which are much more massive mathematical expressions. To easily do so, we must first build some infrastructure.
class Value:
def __init__(
self,
data,
prev=(),
op="",
label="",
):
self.data = data
self.prev = set(prev)
self.op = op
self.label = label
self.grad = 0.0
def __repr__(self):
return f"{self.__class__.__name__}(data='{self.data}'" + (
f", label='{self.label}')" if self.label else ")"
)
def __add__(self, other):
return self.__class__(
data=(self.data + other.data),
prev=(self, other),
op="+",
)
def __radd__(self, other): # other + self
return self + other
def __mul__(self, other):
return self.__class__(
data=(self.data * other.data),
prev=(self, other),
op="*",
)
def __rmul__(self, other): # other * self
return self * other
def __neg__(self): # -self
return self * -1
def __sub__(self, other): # self - other
return self + (-other)
def tanh(self):
return self.__class__(
data=math.tanh(self.data),
prev=(self,),
op="tanh",
)
a = Value(2.0, label="a")
b = Value(-3.0, label="b")
c = Value(10.0, label="c")
f = Value(-2.0, label="f")
def forward_pass(label=False):
d = a * b
e = d + c
L = e * f
if label:
d.label = "d"
e.label = "e"
L.label = "L"
return L
L = forward_pass(label=True)
L
Value(data='-8.0', label='L')
L.prev
{Value(data='-2.0', label='f'), Value(data='4.0', label='e')}
L.op
'*'
The Value object we defined acts as a value holder. It can also perform operations (+, etc.) with other Value objects to produce new Value instances. Each such instance holds:
some value
datathe operation
opthat produced it (e.g.+)its children
prev: a tuple of theValueinstances that produced itits gradient
gradwhich represents the derivative of some value (e.g.L) (w.r.t. the value/instance itself)
To recap what we have done so far: we have built scalar-valued mathematical expression graphs using operations such as addition and multiplication. To see such a graph that each Value object represents, let’s implement visualization function draw() and call it on a Value object, e.g. L.
from graphviz import Digraph
def trace(root):
# builds a set of all nodes and edges in a graph
nodes, edges = set(), set()
def build(v):
if v not in nodes:
nodes.add(v)
for child in v.prev:
edges.add((child, v))
build(child)
build(root)
return nodes, edges
def draw(root):
dot = Digraph(format="svg", graph_attr={"rankdir": "LR"}) # LR = left to right
nodes, edges = trace(root)
for n in nodes:
uid = str(id(n))
# for any value in the graph, create a rectangular ('record') node for it
dot.node(
name=uid,
label="{ %s | data %.4f | grad %.4f}" % (n.label, n.data, n.grad),
shape="record",
)
if n.op:
# if this value is a result of some operation, create an op node for it
dot.node(name=uid + n.op, label=n.op)
# and connect this node to it
dot.edge(uid + n.op, uid)
for n1, n2 in edges:
# connect n1 to the op node of n2
dot.edge(str(id(n1)), str(id(n2)) + n2.op)
return dot
draw(L)

The above graph depicts a forward pass. As a reminder, each grad attribute refers to how much each nudge of the value of a node (e.g. c) contributes to the output value L (i.e. \(\dfrac{\partial L}{\partial c}\)). Let’s now, fill in those gradients by doing backprop manually. Starting at L (the end of the graph), we ask: what is the derivative of L w.r.t. itself? Since \(f(L) = L\), it is: \(\frac{f(L + h) - f(L)}{h} = \frac{L + h - L}{h}\), …
h = 0.001
L.grad = ((L.data + h) - L.data) / h
L.grad
1.000000000000334
…which of course equals \(1\)! Now, moving backwards in the graph, what about the derivative of L w.r.t. e (\(\dfrac{\partial L}{\partial e}\)), for example? Let’s do the same and find out. Since \(L(e) = e \cdot f \Longrightarrow \dfrac{\partial L}{\partial e} = \frac{L(e + h) - L(e)}{h} = \frac{(e + h) \cdot f - e \cdot f}{h} = \frac{e \cdot f + h \cdot f - e \cdot f}{h} = f\). Similarly, \(\dfrac{\partial L}{\partial f} = e\). Therefore:
e.grad = f.data
f.grad = e.data
print(e.grad)
print(f.grad)
-2.0
-7.0
Now, we will find \(\dfrac{\partial L}{\partial c}\), which basically constitutes the crux of backprop for this example and the most important node to understand. So pay attention!
How do we find the derivative of L w.r.t. c? Purely intuitively, just by knowing the sensitivity of L to e (\(\dfrac{\partial L}{\partial e}\)) and how e is sensitive to c (\(\dfrac{\partial e}{\partial c}\)), we should be able to somehow put this information together and get our result. Since we know the former, we just need to find the latter: \(e(c) = c + d\) and so \(\dfrac{\partial e}{\partial c} = \frac{e(c + h) - e(c)}{h} = \frac{(c + h + d) - (c + d)}{h} = 1\). And similarly: \(\dfrac{\partial e}{\partial d} = 1\). That “somehow” is the chain rule, according to which: \(\dfrac{\partial L}{\partial c} = \dfrac{\partial L}{\partial e} \cdot \dfrac{\partial e}{\partial c}\). For us, this means:
c.grad = e.grad * 1.0
c.grad
-2.0
To sum up:
we want \(\dfrac{\partial L}{\partial c}\)
we know \(\dfrac{\partial L}{\partial e}\)
we know \(\dfrac{\partial e}{\partial c}\)
we apply the chain rule: \(\dfrac{\partial L}{\partial c} = \dfrac{\partial L}{\partial e} \cdot \dfrac{\partial e}{\partial c} = \dfrac{\partial L}{\partial e} \cdot 1 = \dfrac{\partial L}{\partial e}\)
similarly: \(\dfrac{\partial L}{\partial d} = \dfrac{\partial L}{\partial e} \cdot \dfrac{\partial e}{\partial d} = \dfrac{\partial L}{\partial e} \cdot 1 = \dfrac{\partial L}{\partial e}\)
Easy! Notice how \(\dfrac{\partial e}{\partial c} = \dfrac{\partial e}{\partial d} = 1\). This equality verifies the fact that the addition operator (+) just acts as a router, merely distributing the derivative of the result (e.g. \(\dfrac{\partial L}{\partial e}\)) backwards, through all the children nodes (e.g. c and d), unperturbed.
To complete this session of manual backprop, we are going to recurse this process and re-apply the chain rule all the way back to the input nodes, a and b. Thus, we are looking for \(\dfrac{\partial L}{\partial a}\) and \(\dfrac{\partial L}{\partial b}\), meaning:
\(\dfrac{\partial L}{\partial a} = \dfrac{\partial L}{\partial d} \cdot \dfrac{\partial d}{\partial a}\)
\(\dfrac{\partial L}{\partial b} = \dfrac{\partial L}{\partial d} \cdot \dfrac{\partial d}{\partial b}\)
We already know that:
f'dL/dd = dL/de = {e.grad}'
'dL/dd = dL/de = -2.0'
But, what about \(\dfrac{\partial d}{\partial a}\) and \(\dfrac{\partial d}{\partial b}\)? Let’s derive them, the same way we did with \(\dfrac{\partial e}{\partial c}\):
\(\dfrac{\partial d}{\partial a} = \frac{d(a + h) - d(a)}{h} = \frac{(a + h) \cdot b - a \cdot b}{h} = b\)
\(\dfrac{\partial d}{\partial b} = a\)
Therefore:
a.grad = e.grad * b.data
b.grad = e.grad * a.data
print(a.grad)
print(b.grad)
6.0
-4.0
If we re-draw our computational graph, we get:
draw(L)

And that’s what backprop is! Just the recursive application of the chain rule backwards through the computational graph for calculating the gradient of a loss value (L) w.r.t. all other values that produced it (a, b, etc.). The purpose being, to be able to use the gradient values to nudge the loss value: optimization. This process goes as follows:
to increase
L, let each value follow the gradient in the positive directionto decrease
L, let each value follow the gradient in the negative direction
Running the following example should increase the value of L:
Lold = L.data
a.data += 0.01 * a.grad
b.data += 0.01 * b.grad
c.data += 0.01 * c.grad
d.data += 0.01 * d.grad
e.data += 0.01 * e.grad
f.data += 0.01 * f.grad
L = forward_pass()
print(f"old L: {Lold}")
print(f"new L: {L.data}")
old L: -8.0
new L: -7.695431999999999
You just learned how to apply one optimization step! Optimization is fundamental when it comes to training nns, as you will see… Eventually we want to build up a level of understanding for training multilayer perceptrons (mlps), as they are called.
Multilayer perceptron example#
from IPython.display import Image, display
display(Image(filename="mlp.jpeg"))
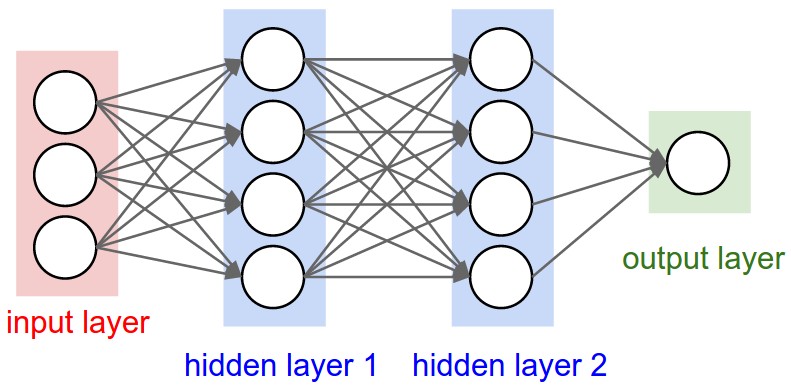
To gain some intuition necessary for training mlps, let’s first explore an example of doing backprop through a simplified neuron.
display(Image(filename="neuron.jpeg"))
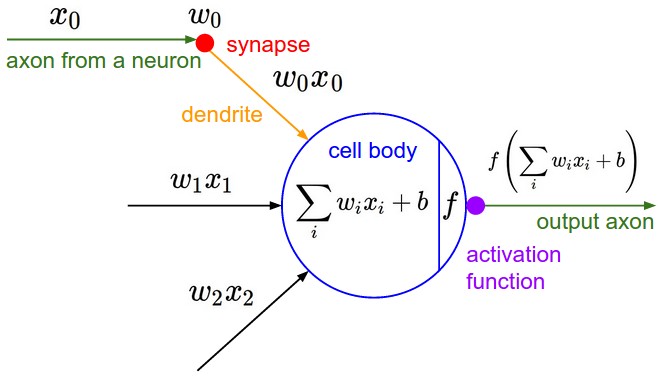
Such a neuron:
receives input \(w_i x_i\) (output \(x_i\) of incoming neuron multiplied by a synaptic weights \(w_i\))
summates those inputs \(\displaystyle \sum_i w_i x_i\) at the cell body
adds a bias \(b\)
passes the result through an activation function \(f\)
outputs the value \(f\bigg(\displaystyle \sum_i w_i x_i + b\bigg)\)
An activation function \(f\) is usually represented by a squashing function such as \(\tanh\):
plt.figure()
plt.plot(np.arange(-5, 5, 0.2), np.tanh(np.arange(-5, 5, 0.2)))
plt.grid();
Let’s extend our Value class to incorporate this tanh activation function:
class Value(Value):
def tanh(self):
return self.__class__(
data=math.tanh(self.data),
prev=(self,),
op="tanh",
)
To simulate the functionality of this neuron:
def activate_neuron():
global x1, x2, w1, w2, b, x1w1, x2w2, sum_, n, o
# inputs x1,x2
x1 = Value(2.0, label="x1")
x2 = Value(0.0, label="x2")
# weights w1,w2
w1 = Value(-3.0, label="w1")
w2 = Value(1.0, label="w2")
# bias of the neuron
b = Value(6.8813735870195432, label="b")
# x1*w1 + x2*w2 + b
x1w1 = x1 * w1
x1w1.label = "x1*w1"
x2w2 = x2 * w2
x2w2.label = "x2*w2"
sum_ = x1w1 + x2w2
sum_.label = "x1*w1 + x2*w2"
n = sum_ + b
n.label = "n"
o = n.tanh()
o.label = "o" # see the newly implemented Value.tanh method
activate_neuron()
draw(o)

As you can see, this graph represents a neuron that takes inputs and weights and produces a value n squashed by an activation function tanh that yields an output o. But, the grad attributes are empty. Let’s fill them up by doing another manual backprop! Doing so requires finding out the derivatives of o w.r.t. the inputs. But of course in a typical nn setting what we really care about the most are the derivatives w.r.t. the weights \(w_i\) (e.g. \(\dfrac{\partial L}{\partial w_i}\)) because those are the free parameters that are usually changed when improving performance.
o.grad = 1.0
o.grad
1.0
\(\dfrac{\partial o}{\partial n} = \dfrac{\partial \tanh(n)}{\partial n} = 1 - \tanh(n)^2\), according to the derivatives of hyperbolic functions. And therefore:
n.grad = 1 - o.data**2
n.grad
0.4999999999999998
And since we learnt from before that the + operation acts as a gradient router and we can see from our graph that n is recursively preceeded by two + operations, the children nodes’ grad attribute will be the same value as n.grad:
x2w2.grad = x1w1.grad = sum_.grad = b.grad = n.grad
x2w2.grad
0.4999999999999998
And according to the chain rule, as previously described, the derivatives of the outputs w.r.t. to the inputs will be:
\(\dfrac{\partial o}{\partial x_1} = \dfrac{\partial o}{\partial {(x_1 \cdot w_1)}} \cdot \dfrac{\partial {(x_1 \cdot w_1)}}{\partial x_1} = \dfrac{\partial o}{\partial {(x_1 \cdot w_1)}} \cdot w_1\)
\(\dfrac{\partial o}{\partial w_1} = \dfrac{\partial o}{\partial {(x_1 \cdot w_1)}} \cdot \dfrac{\partial {(x_1 \cdot w_1)}}{\partial w_1} = \dfrac{\partial o}{\partial {(x_1 \cdot w_1)}} \cdot x_1\)
\(\dfrac{\partial o}{\partial x_2} = \dfrac{\partial o}{\partial {(x_2 \cdot w_2)}} \cdot \dfrac{\partial {(x_2 \cdot w_2)}}{\partial x_2} = \dfrac{\partial o}{\partial {(x_2 \cdot w_2)}} \cdot w_2\)
\(\dfrac{\partial o}{\partial w_2} = \dfrac{\partial o}{\partial {(x_2 \cdot w_2)}} \cdot \dfrac{\partial {(x_2 \cdot w_2)}}{\partial w_2} = \dfrac{\partial o}{\partial {(x_2 \cdot w_2)}} \cdot x_2\)
Thus:
x1.grad = x1w1.grad * w1.data
w1.grad = x1w1.grad * x1.data
x2.grad = x2w2.grad * w2.data
w2.grad = x2w2.grad * x2.data
print(x1.grad)
print(w1.grad)
print(x2.grad)
print(w2.grad)
-1.4999999999999993
0.9999999999999996
0.4999999999999998
0.0
draw(o)

Done. Ok now, doing manual backprop is obviously ridiculous! So, we are gonna put an end to our suffering and see how we can do the backward pass automatically by codifying what we have learnt so far. Specifically, inside each operation of a Value instance, we will define a backward function that calculates the gradient:
class Value(Value):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._backward = lambda: None
def __add__(self, other):
other = other if isinstance(other, self.__class__) else self.__class__(other)
out = super().__add__(other)
def _backward():
self.grad += 1.0 * out.grad
other.grad += 1.0 * out.grad
out._backward = _backward
return out
def __mul__(self, other):
other = other if isinstance(other, self.__class__) else self.__class__(other)
out = super().__mul__(other)
def _backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
def tanh(self):
out = super().tanh()
def _backward():
self.grad += (1 - out.data**2) * out.grad
out._backward = _backward
return out
Notice how we accumulate each gradient (+=) instead of just assigning it (=). This guarantees that multiple backward calls on the same node are not overwritten, ensuring that the gradient is properly accumulated. This reflects the contributions from all paths leading to that node which respects the multivariable case of the chain rule. Now, with our enhanced class, let’s reactivate the neuron and calculate its new output:
activate_neuron()
Then, let’s do automatic backprop with the help of the backward functions we just defined. Calling backward on a value node will populate the grad attribute of the value nodes that produced it: essentially backprop.
o.grad = 1.0 # base case
o._backward()
n._backward()
b._backward() # leaf node: nothing happens!
sum_._backward()
x2w2._backward()
x1w1._backward()
x2._backward() # leaf node: nothing happens!
w2._backward() # leaf node: nothing happens!
x1._backward() # leaf node: nothing happens!
w1._backward() # leaf node: nothing happens!
draw(o)

Hurray! Awesome. We managed to ease the pain of manually calculating the gradients of each node. However, there’s a problem: calling backward on a node (e.g. x1w1) will only work if backward has already been called on its descendant node(s) (e.g. n). In our graph topology this means that backward must be called from the rightmost to the leftmost nodes. This can be done easily by laying out our graph using topological sorting. Below, we re-do the forward pass and define a function that does so:
activate_neuron()
topo = []
visited = set()
def build_topo(v):
if v not in visited:
visited.add(v)
for child in v.prev:
build_topo(child)
topo.append(v)
build_topo(o)
topo
[Value(data='1.0', label='w2'),
Value(data='0.0', label='x2'),
Value(data='0.0', label='x2*w2'),
Value(data='-3.0', label='w1'),
Value(data='2.0', label='x1'),
Value(data='-6.0', label='x1*w1'),
Value(data='-6.0', label='x1*w1 + x2*w2'),
Value(data='6.881373587019543', label='b'),
Value(data='0.8813735870195432', label='n'),
Value(data='0.7071067811865477', label='o')]
Basically, it adds children nodes first before adding non-children nodes. For examples, the first node in the resulting topo list is a child node. Whereas, the non-child node o is last. In essence, what this sorting allows us to do is to traverse the graph and recursively call backward in a safe way, solving the aforementioned problem and thus facilitating automatic backprop with a single call. Something like this:
o.grad = 1.0
for node in reversed(topo):
node._backward()
draw(o)

Let’s incorporate this feature into our new Value class:
class Value(Value):
def backward(self):
topo = []
visited = set()
def build_topo(v):
if v not in visited:
visited.add(v)
for child in v.prev:
build_topo(child)
topo.append(v)
build_topo(self)
self.grad = 1.0
for node in reversed(topo):
node._backward()
To verify it works, we reactivate our neuron and produce a new output:
activate_neuron()
and verify our one-call backprop works:
o.backward()
draw(o)

Voilà! backprop with a single backward call. Let’s test it out one more time:
a = Value(-2.0, label="a")
b = Value(3.0, label="b")
c = a * b
c.label = "c"
d = a + b
d.label = "d"
e = d * c
e.label = "e"
e.backward()
draw(e)

Nice. That was easy… right? Next up, just to prove that this process works more generally, let’s add a few more complex operations to our Value class. First, a power operation:
class Value(Value):
def __pow__(self, other):
assert isinstance(
other, (int, float)
), "only supporting int/float powers for now"
out = self.__class__(
data=self.data**other,
prev=(self,),
op=f"**{other}",
)
def _backward():
self.grad += other * (self.data ** (other - 1)) * out.grad
out._backward = _backward
return out
a = Value(2.0)
b = 3.0
c = a**b
c.grad = 1.0
c._backward()
assert a.grad == b * a.data ** (b - 1)
Also, a division operation:
class Value(Value):
def __truediv__(self, other): # self / other
return self * other**-1
a = Value(2.0)
b = Value(4.0)
c = a / b
assert c.data == (a * (1/b.data)).data == (a * b**-1).data
c.grad = 1.0; c._backward()
assert a.grad == 1 / b.data
And last, but not least, an exponentiation operation:
class Value(Value):
def exp(self):
out = self.__class__(
data=math.exp(self.data),
prev=(self,),
op="exp",
)
def _backward():
self.grad += out.data * out.grad
out._backward = _backward
return out
a = Value(2.0)
a_exp = a.exp()
a_exp.grad = 1.0; a_exp._backward()
assert a.grad == a_exp.data
Using these newly defined operations, we can now explicitly define our own tanh operation, expressed as a composite operation, consisting of a combination of operations, as follows:
class Value(Value):
def tanh(self):
e = (2 * self).exp()
return (e - 1) / (e + 1)
a = Value(2.0)
a_tanh = a.tanh()
a_tanh.backward()
assert math.isclose(a.grad, (1 - a_tanh.data**2))
Furthermore, reactivating the neuron, now with the new composite tanh, and doing backprop:
activate_neuron()
o.backward()
yields…
draw(o)

…the same gradients as before! In the end, what matters is being able to do a functional forward pass and backward pass (backprop) on the output of any of such operation we have defined, no matter how “composite” it is. If you apply the chain rule properly, as demonstrated, the design of the function and it’s complexity are totally up to you. As long as the backward processes are correct, properly, all is good.
So now let’s do the exact same thing using a modern deep neural network library, like PyTorch, on which micrograd is roughly modeled.
import torch
In PyTorch, the equivalent of our Value object is the Tensor object. Tensors are just n-dimensional arrays of scalars. Examples:
torch.Tensor([2.0]) # 1x1 tensor
torch.Tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]) # 2x3 tensor
tensor([[1., 2., 3.],
[4., 5., 6.]])
Like micrograd, PyTorch let’s us construct the mathematical expression of a neuron function on which we can perform backprop!
x1 = torch.tensor([2.0]).double().requires_grad_(True)
x2 = torch.tensor([0.0]).double().requires_grad_(True)
w1 = torch.tensor([-3.0]).double().requires_grad_(True)
w2 = torch.tensor([1.0]).double().requires_grad_(True)
b = torch.tensor([6.8813735870195432]).double().requires_grad_(True)
n = x1 * w1 + x2 * w2 + b
o = torch.tanh(n)
print(o.data.item())
o.backward()
print("---")
print("x2", x2.grad.item())
print("w2", w2.grad.item())
print("x1", x1.grad.item())
print("w1", w1.grad.item())
0.7071066904050358
---
x2 0.5000001283844369
w2 0.0
x1 -1.5000003851533106
w1 1.0000002567688737
tensor() makes a tensor, double() casts it to a double-precision data type (as Python also does, by default) and requires_grad_() enables gradient calculation for that tensor. In PyTorch, one has to explicitly enable it, as gradient calculation is disabled by default for efficiency reasons. Above, we just use single-element scalar tensors. But the whole point of PyTorch is to work with multi-dimensional tensors that can be acted upon in parallel by many different operations. Nevertheless, what we have built very much agrees with the API of PyTorch! Let’s now construct the mathematical expression that constitutes a nn, piece by piece, specifically a 2-layer mlp. We’ll start out by writing up a neuron as we’ve implemented it so far, but making it subscribe to the PyTorch API model in how it designs its own nn modules.
import random
class Neuron:
def __init__(self, nin):
self.w = [Value(random.uniform(-1, 1)) for _ in range(nin)]
self.b = Value(random.uniform(-1, 1))
w is an array of values that represents the weights of the nin input neurons and the bias b of this neuron. Now, we are gonna implement the forward pass call: the sum of the products of each w and input x and b (\(\sum_i w_i x_i + b\)) passed through a non-linear activation function (e.g. tanh).
class Neuron(Neuron):
# w * x + b
def __call__(self, x):
preact = sum((w * x for w, x in zip(self.w, x)), self.b)
out = preact.tanh()
return out
Here’s an example of passing two inputs x through the neuron:
x = [2.0, 3.0]
nin = len(x)
n = Neuron(nin)
n(x)
Value(data='-0.43235771996736344')
Having done so, let’s create a Layer object that represents a layer composed of many neurons as in typical nn fashion. It takes the number of input and output neurons (nin, nout) as arguments.
class Layer:
def __init__(self, nin, nout):
self.neurons = [Neuron(nin) for _ in range(nout)]
def __call__(self, x):
outs = [n(x) for n in self.neurons]
return outs[0] if len(outs) == 1 else outs
Here’s an example of passing two inputs x through a layer of neurons:
x = [2.0, 3.0]
nin = len(x)
nout = 3
l = Layer(nin, nout)
l(x)
[Value(data='0.43948525359013224'),
Value(data='-0.9903943088037261'),
Value(data='0.9985533287198426')]
As expected, after passing in nin input values, we get nout output values. Finally, let’s implement an mlp, in which layers basically feed into each other sequentially. First, we’ll define a constructor that creates a list of layers, each one initialized with the proper number of inputs and outputs, given an initial nin and nouts list. Then, a forward pass method that passes an initial input x through each of the layers, from first to last.
class MLP:
def __init__(self, nin, nouts):
sz = [nin] + nouts
self.layers = [Layer(sz[i], sz[i + 1]) for i in range(len(nouts))]
def __call__(self, x):
for l in self.layers:
x = l(x)
return x
Here’s an example reconstructing the mlp example we saw previously. It has 3 input neurons, two hidden 4-neuron layers and a 1-neuron output layer, therefore:
mlp = MLP(3, [4, 4, 1])
x = [2.0, 3.0, -1.0]
mlp_out = mlp(x)
mlp_out
Value(data='0.8021316553902108')
And if we draw our single mlp output…
draw(mlp_out)

Wow, that’s a big graph! Now obviously, no one sane enough would dare differentiate these expressions with pen and paper. But with micrograd, you’ll be able backprop all the way through this graph back into the leaf nodes, meaning the weights of our neurons (Neuron.w). To test it out, let’s define our own inputs dataset (xs) to be fed into our mlp, as well as their corresponding target values ys. Basically, a simple binary classifier nn, since input corresponds to either 1.0 or -1.0.
xs = [
[2.0, 3.0, -1.0],
[3.0, -1.0, 0.5],
[0.5, 1.0, 1.0],
[1.0, 1.0, -1.0],
]
ys = [1.0, -1.0, -1.0, 1.0] # desired targets
Each one of the input vectors corresponds to each target value of y. E.g. [2.0, 3.0, -1.0] corresponds to target 1.0, [3.0, -1.0, 0.5] to -1.0, and so on. Now, ys are the desired values. Now, let’s pass xs through our mlp and get the predicted values ypreds:
def forward_pass_mlp(mlp):
return [mlp(x) for x in xs]
ypreds = forward_pass_mlp(mlp)
ypreds
[Value(data='0.8021316553902108'),
Value(data='0.694914372587992'),
Value(data='0.8630928931795546'),
Value(data='0.9566959159578626')]
As you can see, currently, our mlp outputs values (ypreds) that are different from the desired target values we want (ys). So, how do we make ypreds equal, or at least as close as possible, to ys? Specifically, how do we tune the weights (aka, train our nn w.r.t. them) in order to better predict the desired targets? The trick used in deep learning that helps us achieve this, is to calculate a single number that somehow measures how well the nn is performing. This number is called the loss. Right now, ypreds is not close to ys, so we are not perfoming very well, meaning that the loss value is high. Our goal is to minimize the loss value and, by doing so, bring ypreds closer to ys. One way to calculate the loss value is through the mean squared error (MSE) function. This function will iterate over pairs of ys and ypreds and sum the squares of their differences. The squared difference of two values (e.g. a prediction and target value) discards any negative signs and gives us a positive quantification that represents how those values differ: their loss. If the loss is zero, the two values do not differ and are equal. Whereas if the loss is another, non-zero number, the two values are different and unequal. In general, the more two values differ, the greater their loss will be. The less they differ, the lower their loss will be. The final MSE loss of all such pairs will just be the sum of all the squared differences:
def calc_loss(ypreds, ys):
return sum([(ypreds - y) ** 2 for ypreds, y in zip(ypreds, ys)])
loss = calc_loss(ypreds, ys)
Now we want to minimize the loss, because if the loss is low, then every one of the predictions is equal to its target. The lowest the loss value can be is 0 (the ideal value). Whereas, the greater it is, the worse off the nn is predicting. So, how do we minimize the loss? First, backprop!
loss.backward()
After a backward call, something magical happens! All gradients of the loss w.r.t. the weights of our mlp get calculated. To see this with our eyes, let’s print out the grad attribute of any of the weights, e.g.:
mlp.layers[0].neurons[0].w[0].grad
-0.15533830793163983
We see that because the gradient of this particular weight of this particular neuron of this particular layer of our nn is negative, we infer that its influence on the loss is also negative. Which means, that slightly increasing this particular weight, would make the loss value go down. Now if we draw the loss…
draw(loss)

we see that it’s massive! The reason is that the loss depends on all the values produced by forward passing all the x values contained in xs into the mlp. Now, although the gradients of all the values in the graph have been calculated, we only care about the gradients of the parameters we want to change, namely the weights and biases. So, our next steps are to gather those parameters and tune them by nudging them based on their gradient information. To do so, we first extend the mlp component classes by implementing parameter getter methods:
class Neuron(Neuron):
def parameters(self):
return self.w + [self.b]
class Layer(Layer):
def parameters(self):
return [p for neuron in self.neurons for p in neuron.parameters()]
class MLP(MLP):
def parameters(self):
return [p for layer in self.layers for p in layer.parameters()]
After getting our output and loss again (due to redefining the classes)…
mlp = MLP(3, [4, 4, 1])
ypreds = forward_pass_mlp(mlp)
loss = calc_loss(ypreds, ys)
loss.backward()
we may inspect all the parameters…
mlp_params = mlp.parameters()
print(mlp_params)
print(len(mlp_params))
[Value(data='-0.5891124237861678'), Value(data='0.28090981749146215'), Value(data='0.7547091264633694'), Value(data='-0.5146778088364283'), Value(data='0.8672995598598101'), Value(data='0.7406510232644734'), Value(data='0.5288406626421873'), Value(data='0.08447495239111946'), Value(data='-0.6563246126894655'), Value(data='0.3981255695120931'), Value(data='-0.012968303988030394'), Value(data='0.7542094002676307'), Value(data='0.0033286930198876963'), Value(data='0.2556304142635857'), Value(data='-0.9314080289080375'), Value(data='0.4054173907532759'), Value(data='0.774679311925067'), Value(data='-0.18811978158086262'), Value(data='0.7575932811823123'), Value(data='0.4477844375844444'), Value(data='0.39651768767863205'), Value(data='0.05901494877107494'), Value(data='0.8809980312429269'), Value(data='-0.7064254928263687'), Value(data='0.17787965036070652'), Value(data='0.9795480701510118'), Value(data='-0.345249225309854'), Value(data='0.5363299378699073'), Value(data='-0.34760846138944257'), Value(data='0.7486671457569554'), Value(data='0.7160267321114855'), Value(data='0.5698199508762045'), Value(data='-0.5563952037955955'), Value(data='-0.4432545915770989'), Value(data='-0.7637467843038042'), Value(data='0.46496054602256986'), Value(data='-0.8182517028250273'), Value(data='-0.6649446947755555'), Value(data='0.39870787529352847'), Value(data='-0.37824313155178624'), Value(data='-0.884314155961383')]
41
and change them in a manner that decreases the loss. Before we optimize all of them though, let’s first optimize only one to see exactly how the process is done:
mlp.layers[0].neurons[0].w[0].grad
0.34342225762161804
mlp.layers[0].neurons[0].w[0].data
-0.5891124237861678
To understand how to optimize the parameters, we need to understand the relationship between grad and loss through two distinct cases:
A. A parameter’s positive grad (> 0) value tells us that:
(1) increasing that parameter would increase the loss
(2) decreasing that parameter would decrease the loss
B. A parameter’s negative grad (< 0) value tells us that:
(1) increasing that parameter would decrease the loss
(2) decreasing that parameter would increase the loss
Since, we only care about decreasing the loss (since we want to minimize it), we only care about cases A2 and B1. Therefore, we now know that decreasing the loss depends on changing the weight by an amount whose sign is the opposite of the grad value. Since the opposite of a value is just its negation, we describe the general optimization step required to change each parameter as follows:
To decrease the loss, change each parameter
pin the direction that is opposite the direction of the the gradientgradof the loss w.r.t.p(\(\dfrac{\partial loss}{\partial p}\)).
This can be achieved by subtracting the product of the gradient and a small step size \(\alpha\) from the current parameter value:
\(p = p - \alpha\dfrac{\partial loss}{\partial p}\), where \(α\) is a usually small positive number (e.g. \(0.001\)) called the learning rate, which determines how big of a step size is to be taken during the optimization step. Since we descend the gradient, we call this process gradient descent. Let’s now optimize one weight parameter with one step of gradient descent:
ypreds = forward_pass_mlp(mlp)
loss = calc_loss(ypreds, ys)
# zero out gradients (so they don't accummulate)
for p in mlp.parameters():
p.grad = 0.0
loss.backward()
mlp.layers[0].neurons[0].w[0].data += -0.001 * mlp.layers[0].neurons[0].w[0].grad
ypreds_after = forward_pass_mlp(mlp)
loss_after = calc_loss(ypreds_after, ys)
print(f"Loss before optimization step: {loss}")
print(f"Loss after optimization step: {loss_after}")
Loss before optimization step: Value(data='6.606895868054532')
Loss after optimization step: Value(data='6.6067779753029345')
See? Loss after the step is lower than before it. So, optimizing even one parameter with this procedure, decreases the loss of our mlp! But in order to decrease it even more, let alone minimize it, we must also optimize all of the parameters. How? Like this:
ypreds = forward_pass_mlp(mlp)
loss = calc_loss(ypreds, ys)
# zero gradients (so they don't accummulate)
for p in mlp.parameters():
p.grad = 0.0
loss.backward()
for p in mlp.parameters():
p.data += -0.001 * p.grad
ypreds_after = [mlp(x) for x in xs]
loss_after = sum([(ypreds - y) ** 2 for ypreds, y in zip(ypreds_after, ys)])
print(f"Loss before optimization step: {loss}")
print(f"Loss after optimization step: {loss_after}")
print([y.data for y in ypreds])
print([y.data for y in ypreds_after])
print(ys)
Loss before optimization step: Value(data='6.6067779753029345')
Loss after optimization step: Value(data='6.56156718545472')
[-0.7786370603743357, -0.41961729625360783, -0.9397577797813043, -0.7614638727095784]
[-0.7716021275092538, -0.41675489429569573, -0.9388225451270673, -0.7547294814149134]
[1.0, -1.0, -1.0, 1.0]
Same thing happens: loss decreases! Most importantly, each time we re-run the optimization, the prediction values get even closer to the target values, which is our primary goal! In general, we must be careful with our step size. Too small of a step size will take many many steps to decrease the loss, whereas too big of a step size might be an overstep that causes an increase instead of a decrease of the loss. Sometimes, if the increase is too big, the loss value explodes. Finding a step size that is just right can be a subtle art sometimes. You can play around with the step size, re-running the cells each time, to see its effect. All in all, we have been able to derive a set of parameters (weights and biases):
mlp.parameters()
[Value(data='-0.5897989998671106'),
Value(data='0.2803740639577263'),
Value(data='0.7550020342196525'),
Value(data='-0.5149260060116513'),
Value(data='0.8673092472790822'),
Value(data='0.7407064996722453'),
Value(data='0.5287909012313932'),
Value(data='0.08450678345753262'),
Value(data='-0.6577188091598949'),
Value(data='0.3963168801724268'),
Value(data='-0.012013893833775947'),
Value(data='0.7532520827391431'),
Value(data='0.002588577562609616'),
Value(data='0.2557082084784828'),
Value(data='-0.931431643158572'),
Value(data='0.40511915330400977'),
Value(data='0.7764577716116262'),
Value(data='-0.189860095784784'),
Value(data='0.7563382171213389'),
Value(data='0.44572918234887604'),
Value(data='0.3945828727895028'),
Value(data='0.05929905243207291'),
Value(data='0.8807232529636616'),
Value(data='-0.7066137541919688'),
Value(data='0.17756069037644506'),
Value(data='0.9792410059041483'),
Value(data='-0.3452696799447055'),
Value(data='0.5363447266323415'),
Value(data='-0.34752650190640577'),
Value(data='0.7487529046819845'),
Value(data='0.7160476085724314'),
Value(data='0.5696464123075088'),
Value(data='-0.5562098813916081'),
Value(data='-0.4436842004682603'),
Value(data='-0.7640376420712507'),
Value(data='0.4651341160686098'),
Value(data='-0.8165050609850243'),
Value(data='-0.6632768321623527'),
Value(data='0.40059372617437855'),
Value(data='-0.3808573235417481'),
Value(data='-0.8824037909061284')]
that makes our network predict the target values. Basically, we have learned how to train a nn! But, let’s make it a bit more respectable by implementing a training loop.
for k in range(20):
# forward pass
ypreds = forward_pass_mlp(mlp)
loss = calc_loss(ypreds, ys)
# zero gradients (so they don't accummulate)
for p in mlp.parameters():
p.grad = 0.0
# backward pass
loss.backward()
# update
for p in mlp.parameters():
p.data += -0.05 * p.grad
print(k, loss.data)
0 6.56156718545472
1 3.1886742323366386
2 1.3032015611952863
3 0.769939759300913
4 0.5477680622174333
5 0.4342573296227225
6 0.3561670649634663
7 0.2988718838759568
8 0.255522186577933
9 0.2218579442103602
10 0.19512822582659206
11 0.17349684405903604
12 0.15570168219740943
13 0.14085232054584612
14 0.12830585626266888
15 0.11758842447875281
16 0.10834425517148419
17 0.1003017900448846
18 0.09325064258909059
19 0.08702561304645334
After training, the prediction values should be significantly closer to target values:
print([y.data for y in ypreds])
print(ys)
[0.8563656958279531, -0.7991263758236825, -0.9425547459839091, 0.849186772421105]
[1.0, -1.0, -1.0, 1.0]
Training demo#
Last but not least, let’s implement a small yet full demo of training an 2-layer nn (MLP) binary classifier. This is achieved by initializing a nn from micrograd.nn module, implementing a simple svm “max-margin” binary classification loss and using SGD for optimization. Try and figure out what is happening here by reading the code!
from sklearn.datasets import make_moons
np.random.seed(1337)
random.seed(1337)
# make up a dataset
X_moons, y_moons = make_moons(n_samples=100, noise=0.1)
y_moons = y_moons * 2 - 1 # make y be -1 or 1
# visualize in 2D
plt.figure(figsize=(5, 5))
plt.scatter(X_moons[:, 0], X_moons[:, 1], c=y_moons, s=20, cmap="jet");
from micrograd.nn import MLP
# initialize a model
model = MLP(2, [16, 16, 1]) # 2-layer neural network
print(model)
print("number of parameters", len(model.parameters()))
MLP of [Layer of [ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2)], Layer of [ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16), ReLUNeuron(16)], Layer of [LinearNeuron(16)]]
number of parameters 337
from micrograd.engine import Value
# loss function
def loss(batch_size=None):
# inline DataLoader :)
if batch_size is None:
Xb, yb = X_moons, y_moons
else:
ri = np.random.permutation(X_moons.shape[0])[:batch_size]
Xb, yb = X_moons[ri], y_moons[ri]
inputs = [list(map(Value, xrow)) for xrow in Xb]
# forward the model to get scores
scores = list(map(model, inputs))
# svm "max-margin" loss
losses = [(1 + -yi * scorei).relu() for yi, scorei in zip(yb, scores)]
data_loss = sum(losses) * (1.0 / len(losses))
# L2 regularization
alpha = 1e-4
reg_loss = alpha * sum((p * p for p in model.parameters()))
total_loss = data_loss + reg_loss
# also get accuracy
accuracy = [(yi > 0) == (scorei.data > 0) for yi, scorei in zip(yb, scores)]
return total_loss, sum(accuracy) / len(accuracy)
total_loss, acc = loss()
print(total_loss, acc)
Value(data=0.8958441028683222, grad=0) 0.5
# optimization
for k in range(100):
# forward
total_loss, acc = loss()
# backward
model.zero_grad()
total_loss.backward()
# update (sgd)
learning_rate = 1.0 - 0.9 * k / 100
for p in model.parameters():
p.data -= learning_rate * p.grad
if k % 1 == 0:
print(f"step {k} loss {total_loss.data}, accuracy {acc*100}%")
step 0 loss 0.8958441028683222, accuracy 50.0%
step 1 loss 1.7235905336972022, accuracy 81.0%
step 2 loss 0.742900631385113, accuracy 77.0%
step 3 loss 0.7705641260584201, accuracy 82.0%
step 4 loss 0.36927933859765383, accuracy 84.0%
step 5 loss 0.313545481918522, accuracy 86.0%
step 6 loss 0.2814234349772434, accuracy 89.0%
step 7 loss 0.2688873331398391, accuracy 91.0%
step 8 loss 0.2567147286057417, accuracy 91.0%
step 9 loss 0.2704862551637922, accuracy 91.0%
step 10 loss 0.2450702385365804, accuracy 91.0%
step 11 loss 0.25099055297915035, accuracy 92.0%
step 12 loss 0.2156095185192295, accuracy 91.0%
step 13 loss 0.23090378446402726, accuracy 93.0%
step 14 loss 0.20152151227899445, accuracy 92.0%
step 15 loss 0.2257450627928222, accuracy 93.0%
step 16 loss 0.19447987596204108, accuracy 92.0%
step 17 loss 0.21089496199246363, accuracy 93.0%
step 18 loss 0.15983077356303602, accuracy 94.0%
step 19 loss 0.18453748746883916, accuracy 93.0%
step 20 loss 0.1897752285608764, accuracy 91.0%
step 21 loss 0.19072704042579644, accuracy 93.0%
step 22 loss 0.11733695088756486, accuracy 97.0%
step 23 loss 0.12173524408232453, accuracy 95.0%
step 24 loss 0.12615712612770452, accuracy 95.0%
step 25 loss 0.16049097780801674, accuracy 95.0%
step 26 loss 0.1874719770524581, accuracy 92.0%
step 27 loss 0.16741837891059402, accuracy 95.0%
step 28 loss 0.09586583491455397, accuracy 97.0%
step 29 loss 0.08778783707420913, accuracy 96.0%
step 30 loss 0.1173129756901185, accuracy 95.0%
step 31 loss 0.09340146460619832, accuracy 97.0%
step 32 loss 0.12454454903103453, accuracy 95.0%
step 33 loss 0.07984002652777268, accuracy 97.0%
step 34 loss 0.07727519232921673, accuracy 97.0%
step 35 loss 0.07661250143094474, accuracy 98.0%
step 36 loss 0.10610492379198366, accuracy 96.0%
step 37 loss 0.0906280842926597, accuracy 99.0%
step 38 loss 0.10671887043036926, accuracy 95.0%
step 39 loss 0.052256599219758455, accuracy 98.0%
step 40 loss 0.06016009895234463, accuracy 100.0%
step 41 loss 0.08596724533333938, accuracy 96.0%
step 42 loss 0.05112107943179595, accuracy 99.0%
step 43 loss 0.05240142401642826, accuracy 97.0%
step 44 loss 0.04530684179001569, accuracy 100.0%
step 45 loss 0.07211073370655094, accuracy 97.0%
step 46 loss 0.0333423865131023, accuracy 99.0%
step 47 loss 0.03143222795751125, accuracy 100.0%
step 48 loss 0.03658536747111507, accuracy 99.0%
step 49 loss 0.048291393823903, accuracy 99.0%
step 50 loss 0.09875114765619629, accuracy 96.0%
step 51 loss 0.05449063965875445, accuracy 99.0%
step 52 loss 0.03392679435708304, accuracy 100.0%
step 53 loss 0.05261517263568441, accuracy 97.0%
step 54 loss 0.03250295251424922, accuracy 99.0%
step 55 loss 0.028883273872078178, accuracy 100.0%
step 56 loss 0.0413915110402724, accuracy 98.0%
step 57 loss 0.018987407426128484, accuracy 100.0%
step 58 loss 0.02523833523883741, accuracy 100.0%
step 59 loss 0.020796565213418904, accuracy 100.0%
step 60 loss 0.032597111578102314, accuracy 99.0%
step 61 loss 0.017863351693480252, accuracy 100.0%
step 62 loss 0.023008717832211714, accuracy 100.0%
step 63 loss 0.02207932546358144, accuracy 100.0%
step 64 loss 0.029432917853529687, accuracy 99.0%
step 65 loss 0.016251514644091886, accuracy 100.0%
step 66 loss 0.028468534483264467, accuracy 99.0%
step 67 loss 0.013994365546208726, accuracy 100.0%
step 68 loss 0.015552344843651377, accuracy 100.0%
step 69 loss 0.03389119946160171, accuracy 99.0%
step 70 loss 0.014229870065926912, accuracy 100.0%
step 71 loss 0.013255281583285499, accuracy 100.0%
step 72 loss 0.012300277590022056, accuracy 100.0%
step 73 loss 0.012676052498355978, accuracy 100.0%
step 74 loss 0.02059381195595472, accuracy 100.0%
step 75 loss 0.01184539820536442, accuracy 100.0%
step 76 loss 0.01601269747288313, accuracy 100.0%
step 77 loss 0.025458360239222075, accuracy 100.0%
step 78 loss 0.014382930289661883, accuracy 100.0%
step 79 loss 0.011698962425817966, accuracy 100.0%
step 80 loss 0.012318500800515811, accuracy 100.0%
step 81 loss 0.014121117031464226, accuracy 100.0%
step 82 loss 0.01166459196244621, accuracy 100.0%
step 83 loss 0.011589314549188727, accuracy 100.0%
step 84 loss 0.010990299347735226, accuracy 100.0%
step 85 loss 0.01098922672069161, accuracy 100.0%
step 86 loss 0.010988193757655071, accuracy 100.0%
step 87 loss 0.010987200447388707, accuracy 100.0%
step 88 loss 0.010986246779084925, accuracy 100.0%
step 89 loss 0.010985332742365276, accuracy 100.0%
step 90 loss 0.010984458327280174, accuracy 100.0%
step 91 loss 0.010983623524308865, accuracy 100.0%
step 92 loss 0.010982828324359074, accuracy 100.0%
step 93 loss 0.010982072718767003, accuracy 100.0%
step 94 loss 0.010981356699297043, accuracy 100.0%
step 95 loss 0.010980680258141725, accuracy 100.0%
step 96 loss 0.010980043387921508, accuracy 100.0%
step 97 loss 0.010979446081684675, accuracy 100.0%
step 98 loss 0.010978888332907227, accuracy 100.0%
step 99 loss 0.010978370135492717, accuracy 100.0%
# visualize decision boundary
h = 0.25
x_min, x_max = X_moons[:, 0].min() - 1, X_moons[:, 0].max() + 1
y_min, y_max = X_moons[:, 1].min() - 1, X_moons[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Xmesh = np.c_[xx.ravel(), yy.ravel()]
inputs = [list(map(Value, xrow)) for xrow in Xmesh]
scores = list(map(model, inputs))
Z = np.array([s.data > 0 for s in scores])
Z = Z.reshape(xx.shape)
fig = plt.figure()
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X_moons[:, 0], X_moons[:, 1], c=y_moons, s=40, cmap=plt.cm.Spectral)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max());
Summary#
Let’s now bring together and summarize what we have learned. nns are functions that take the data as well as the weights and biases (parameters) as inputs to produce outputs. The outputs, or predictions, together with target values are then passed through a loss function that yields an error called the loss value that represents their distance, in terms of how close or far apart they are. We train nns by using backprop to calculate the gradient of the loss w.r.t. the parameters. These gradients are used to then optimize those parameters using gradient descent in order to minimize the loss. The end goal is for the nn to perform a given task. Although relatively simple expressions, it turns out that nns can solve very complicated problems. Sometimes, if the problem is complex enough, and the nn big enough (> 100 billion parameters), fascinating proprties arise, as in the case of GPT, for example. This model, trained with large amounts of text from the internet can predict, given some words, the next words in a sequence.
Outro#
This brings us to the end of the micrograd tutorial. I hope you enjoyed this tutorial and found it helpful! Next up, it’s time to make more!